Presto can connect to many different “big data” databases and data stores at once, and query across them using SQL syntax.
Presto is Optimized for OLAP – analytical queries, data warehousing.
Presto exposes JDBC, Command-Line, and Tableau interfaces Cassandra , Hive , MongoDB ,MySQL ,Local files,Kafka, JMX, PostgreSQL, Redis.
In this example we will try to connect presto to Hive and cassandra and query and join the tables.
Start HDFS , Hive , Cassandra
Load Data in to Cassandra using Spark
def readUserData() = {
spark.read
.textFile("src/main/resources/ml-100k/u.user")
.map(lines => {
val user = lines.split('|')
UserClass(user(0).toInt,user(1).toInt,user(2).toString,user(3).toString,user(4).toString)
})
}
def writetoCassandra()={
readUserData()
.write
.cassandraFormat("movieusers","hyper")
.mode(SaveMode.Append)
.save()
}
Start Presto
Configure the etc/catalog/hive.properties and cassandra.properties file.
#### hive.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://192.168.1.131:9083
hive.config.resources=/home/hyper/hadoop/hadoop/etc/hadoop/core-site.xml,/home/hyper/hadoop/hadoop/etc/hadoop/hdfs-site.xml
#### cassandra.properties
connector.name=cassandra
cassandra.contact-points=XXX.XXX.1.200
cassandra.native-protocol-port=9042
bin/launcher start
./presto --server XXX.XXX.1.XXX:8090 --catalog hive,cassandra
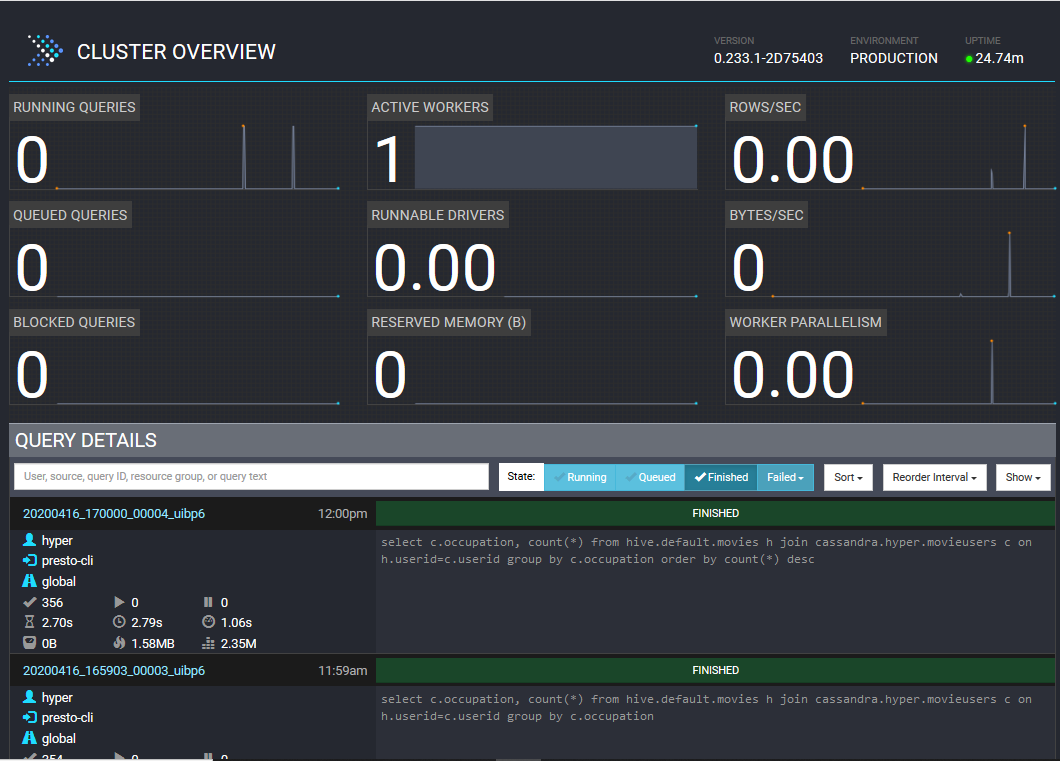
Verify the presto UI
Query Tables from Hive and Cassandra.
select * from hive.default.movies limit 10;
select * from cassandra.hyper.movieusers limit 10;
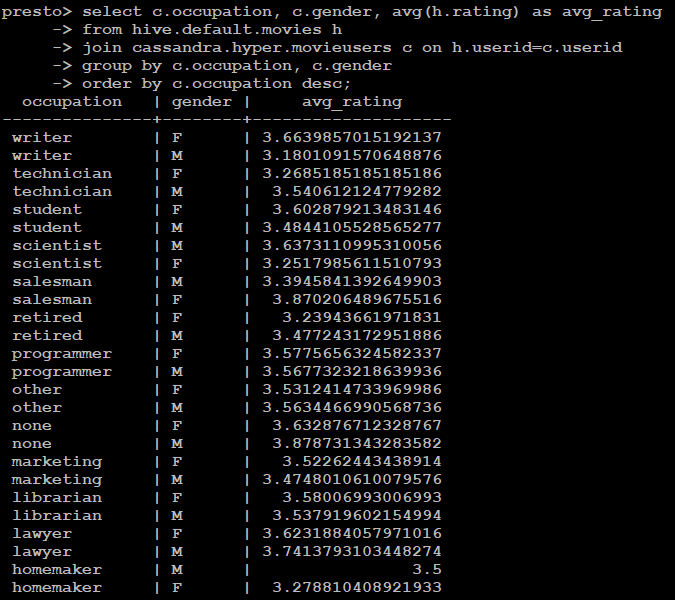
Join both hive and cassandra tables.
select c.occupation, c.gender, avg(h.rating) as avg_rating
from hive.default.movies h
join cassandra.hyper.movieusers c on h.userid=c.userid
group by c.occupation, c.gender
order by c.occupation desc;
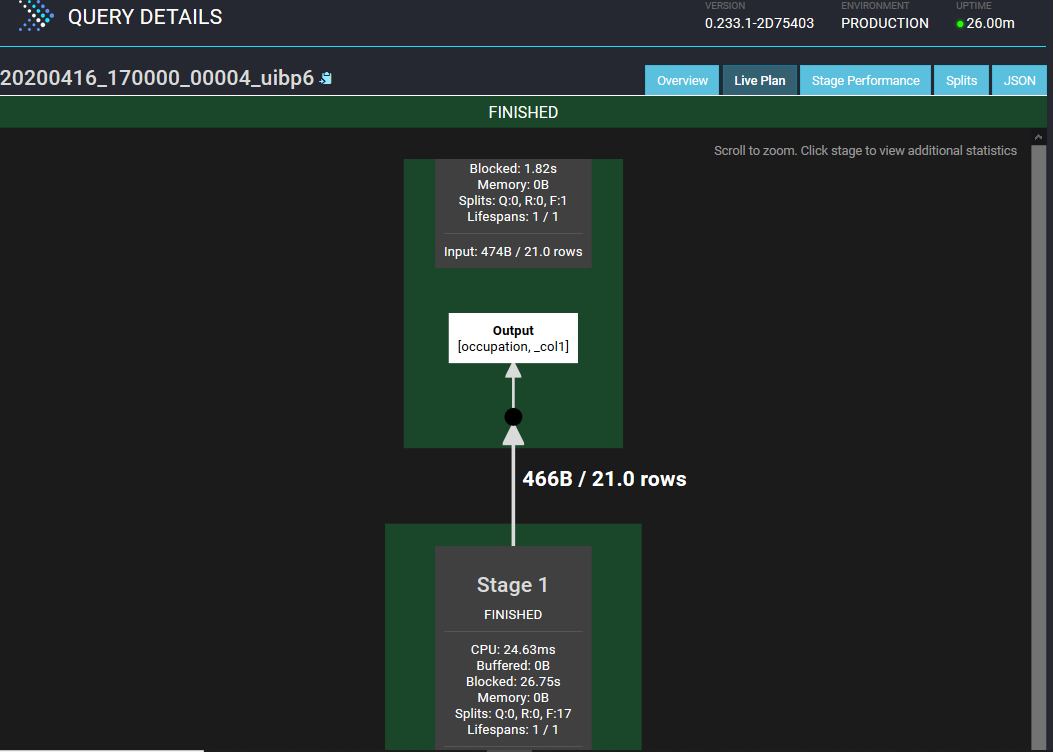
Presto Query Details in UI