Setup Multi-node Cassandra cluster on a single machine
We will create three node Cassandra cluster on single local machine.
Cluster will have 2 Nodes in one datacenter and 3rd node on another datacenter.
For partitioner We will use Murmur3Partitioner.Cassandra distributes data based on tokens. Token Range is determined by partitioner configured in cassandra.yaml file.
We will use GossipingPropertyFileSnitch as snitch for Data Replication between Data Centers.
We will use the DataStax Java Driver api for Apache Cassandra to interreact with cluster using scala.
From the extracted Cassandra directory and make two copies of the conf folder- conf2 and conf3.
Inside the conf, conf2 and conf3 directory make changes to the cassandra.yml file to make all the nodes of our cluster up and running. Cassandra.yaml is the main configuration file for Cassandra.
Changes need to me made to cassandra.yaml for each node in conf , conf2 , conf3 directories.
cluster_name: 'RTRCluster'
num_tokens: 8
hints_directory: /home/hyper/cassandra/data/node1/hints
data_file_directories:
- /home/hyper/cassandra/data/node1
commitlog_directory: /home/hyper/cassandra/data/node1/commitlog
# Change listen address to listen_address: 127.0.0.2, or 127.0.0.3 in each directory
listen_address: 127.0.0.1
# IP address to connect to cluster
rpc_address: 182.168.100.200
# native_transport_port: 9042 9043 9044 for each directory
native_transport_port: 9042
endpoint_snitch: GossipingPropertyFileSnitch
Change JMX_Port under cassandra.env. sh file for conf2 and conf3 folders to 7177,7188,7199.
JMX_Port specifies the default port over which Cassandra will be available for JMX connections.
In bin directory there is a cassandra.in.sh file, make two copies of it naming them cassandra2.in.sh and cassandra3.in.sh.
In cassandra2.in.sh and change cassandra_conf property to point to the correct conf directory.
CASSANDRA_CONF=”$CASSANDRA_HOME/conf2
In bin directory there is a cassandra file, make two copies of it naming them cassandra2 and cassandra3 and specify which config directory it has to use.
CASSANDRA_CONF=/home/hyper/cassandra/cassandra/conf2
We will use GossipingPropertyFileSnitch as snitch for Data Replication between Data Centers.
Edit cassandra-rackdc.properties file in the conf directory. Name 2 of them to be same dc and rack
dc=KATY
rack=RCK-KATY
Snitch uses cassandra-topology.properties as a backup.
Make the below changes in all conf directories.
127.0.0.1=KATY:RCK-KATY
127.0.0.2=KATY:RCK-KATY
127.0.0.3=HOUSTON:RCK-HTWN
Start Cassandra nodes from bin directory.
./cassandra -f
./cassandra2 -f
./cassandra3 -f
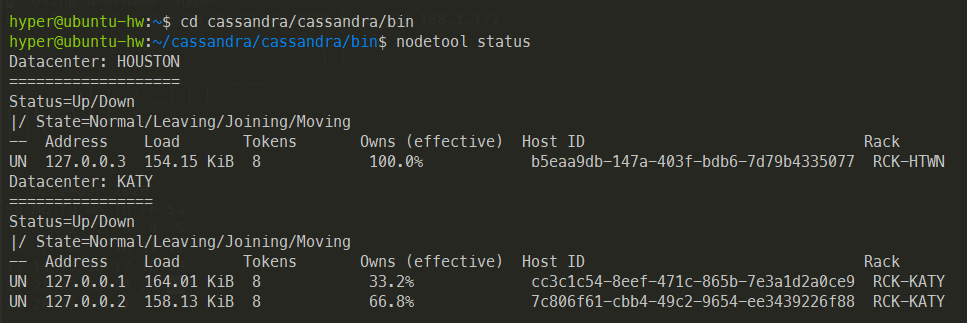
Use nodetool status command to verify the cluster from bin directory.
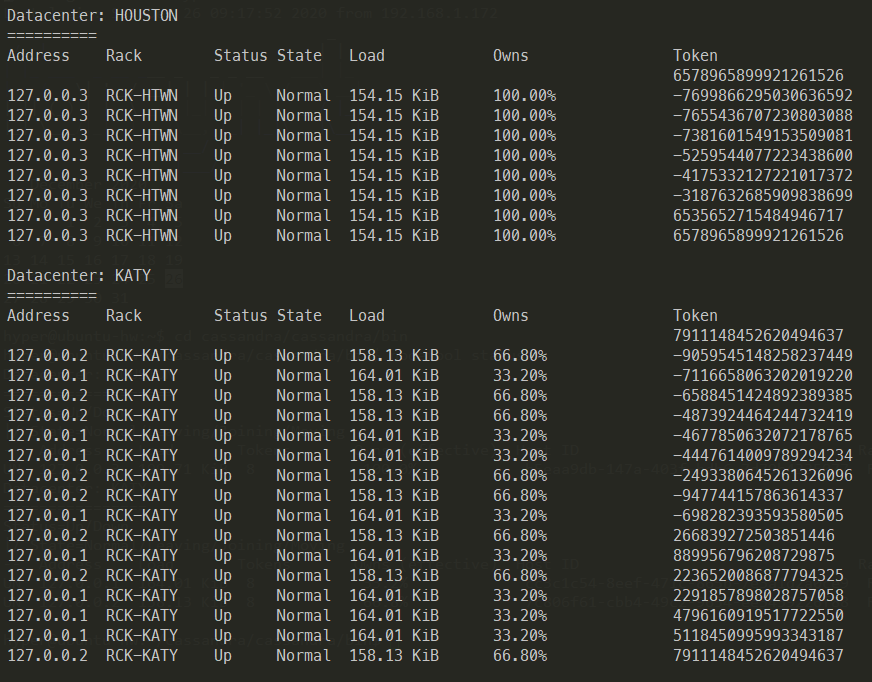
Use nodetool ring command to verify the token creation from bin directory.
We will interact with Cassandra cluster using cassandra-driver-core api.
Add below dependency to build.sbt to the scala project.
//cassandra
"com.datastax.cassandra" % "cassandra-driver-core" % "3.10.2"
Create KeySpace with replication strategy NetworkTopologyStrategy
import com.datastax.driver.core.{Cluster, Session}
val host = "192.168.1.200"
val port = 9042
val clusterName = "RTRCluster"
val cluster: Cluster = Cluster
.builder()
.addContactPoint(host)
.withPort(port)
.withClusterName(clusterName)
.withoutJMXReporting()
.build()
val session: Session = cluster.connect()
val query =
"""
|CREATE KEYSPACE rtrnetwork
|WITH replication = {'class': 'NetworkTopologyStrategy', 'HOUSTON' : 1, 'KATY' : 1}
|AND durable_writes = true;
|""".stripMargin
session.execute(query)
session.close()
cluster.close()
println("KeySpace Created")
Create Table
Use the SchemaBuilder to create table with with compound primary key and clustering keys.
import com.datastax.driver.core.schemabuilder.SchemaBuilder
import com.datastax.driver.core.DataType._
val createTable: Create = SchemaBuilder.createTable("rtrnetwork","schematablecomp")
.ifNotExists()
.addPartitionKey("country", text())
.addPartitionKey("age",cint())
.addClusteringColumn("first_name", text())
.addClusteringColumn("last_name", text())
.addClusteringColumn("id", uuid())
.addColumn("profession", text())
.addColumn("salary", cint())
Insert into Table
Insert into table using QueryBuilder and ConsistencyLevel = QUORUM
import com.datastax.driver.core.querybuilder.QueryBuilder
import com.datastax.driver.core.querybuilder.{Clause, Insert, Select}
import com.datastax.driver.core.ConsistencyLevel
val insertStmt = QueryBuilder.insertInto("rtrnetwork","users")
.value("id",java.util.UUID.randomUUID())
.value("username","Reva")
.setConsistencyLevel(ConsistencyLevel.QUORUM)
session.execute(insertStmt)
Read Data from cluster
val uid:UUID = UUID.fromString("52216da8-bc78-44d9-8e40-983d83c23889")
val whereClause: Clause = QueryBuilder.eq("id",uid)
val queryBuilder = QueryBuilder.select("id","username")
.from("rtrnetwork","users")
.where(whereClause)
.setConsistencyLevel(ConsistencyLevel.QUORUM)
val result: ResultSet = session.execute(queryBuilder)
result.forEach(row => println(row.getUUID("id")))
Delete data
val whereClause: Clause = QueryBuilder.eq("id",uid)
val deleteQuery = QueryBuilder.delete()
.from("rtrnetwork","users")
.where(whereClause)
session.execute(deleteQuery)
Example Using Prepared Statement.
val session = cluster.connect()
case class Person(id:UUID,username:String)
val rupesh = Person(UUID.randomUUID(),"Rupesh")
val useKeySpace = "use rtrnetwork"
val preparedStatement: PreparedStatement = session.prepare(
"""
|insert into rtrnetwork.users(id,username) values(?,?);
|""".stripMargin)
val boundedStatement: BoundStatement = new BoundStatement(preparedStatement)
val bindUsers: BoundStatement = boundedStatement.bind(rupesh.id,rupesh.username)
session.execute(useKeySpace)
session.execute(bindUsers)
session.close()
cluster.close()
println("Insert Bind Completed")
Using bindMarker()
import com.datastax.driver.core.querybuilder.QueryBuilder.bindMarker
val insertStmt = QueryBuilder.insertInto("rtrnetwork","users")
.value("id",bindMarker())
.value("username",bindMarker())
val prepStmt = session.prepare(insertStmt)
val insertRandom: List[Statement] = List.range(1,10).map(user => {
prepStmt.bind()
.setUUID("id",UUID.randomUUID())
.setString("username",s"${rand.alphanumeric.take(10).mkString("")}")
.setConsistencyLevel(ConsistencyLevel.QUORUM)
})
insertRandom.foreach(stmt => session.executeAsync(stmt))
Verify Replication
We are using NetworkTopologyStrategy as strategy for replication.
So the key should the replicated on one node in each data center as per the key space replication strategy we created.
Verify the replication using nodetool getendpoints keyspace tablename keyvalue
In this case nodetool getendpoints rtrnetwork users 07ba76f5-f648-46bf-a614-97f4924bb142

Key is replicated as per the Replication Strategy ‘NetworkTopologyStrategy’, ‘HOUSTON’ : 1, ‘KATY’ : 1