Steps for Deploying Spark App on Amazon EMR
- Make sure there are no paths to your local filesystem used in your script! Use HDFS, S3, etc. instead.
- Package up your Scala project into a JAR file (using Export in the IDE) or SBT Cli.
- Java or Scala package sometimes are not pre-loaded on EMR.(eg kafka connector)
- Bundle them into your JAR with sbt assembly Or use –jars with spark-submit to add individual libraries that are dowloaded on the master node.
- Upload your scripts & data to AWS S3 Bucket where EMR have access. Use s3://bucket-name/filename when specifying file paths, Make sure to set bucket permissions to make the files accessible
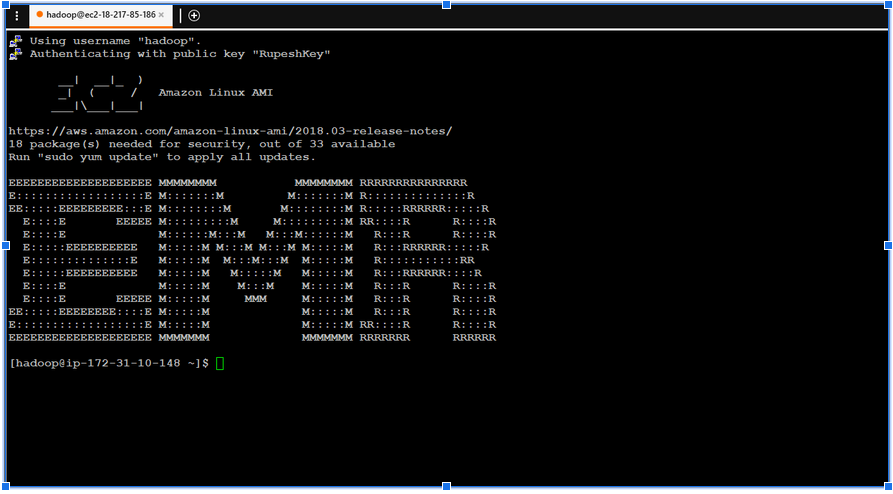
- Spin up an EMR cluster for Spark using the AWS console.AWS Billing Begins when instance starts. Get the external DNS name for the master node, and log into it using the “hadoop” user account and your private key file
- Copy your driver program’s JAR file and any additional files from s3 bucket into aws ec2 instance
-
Use spark-submit to execute your driver script.
spark-submit –class <class object that contains your main function> --jars <paths to any dependencies> --files <files your application needs> <your JAR file>We can use –master yarn to run on a YARN cluster.EMR sets this by default
Use defaults in driver initialization in spark. EMR will use the defaults it sets up , plus any command-line options we pass into spark-submit on the master node. If executors start failing, adjust the memory each executor spark-submit –executor-memory 1g
-
Step 1
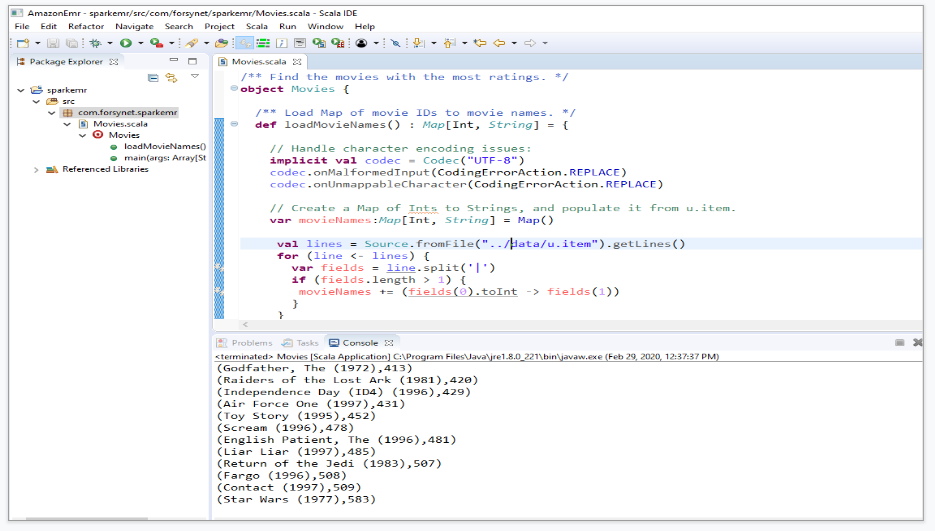
Test your application using Scala - ide using sample data.
-
Step 2
-
Remove all local path and Spark Context master local reference from Scala file.
-
Use SBT to package your application
- Create and empty directory sbt
- sbt new scala/hello-world.g8.
- add your scale files under sbt\movies\src\main\scala directory
- edit sbt\movies\built.sbt
-
name := "MostRatedMovies100k" version := "1.0" organization := "com.forsynet.sparkemr" scalaVersion := "2.11.12" libraryDependencies ++= Seq( "org.apache.spark" %% "spark-core" % "2.4.5" % "provided" ) -
at command prompt run command “sbt assembly”
- This will create jar files with all dependencies under sbt\movies\target\scala-2.11\MostRatedMovies100k-assembly-1.0.jar
-
-
Step 3
-
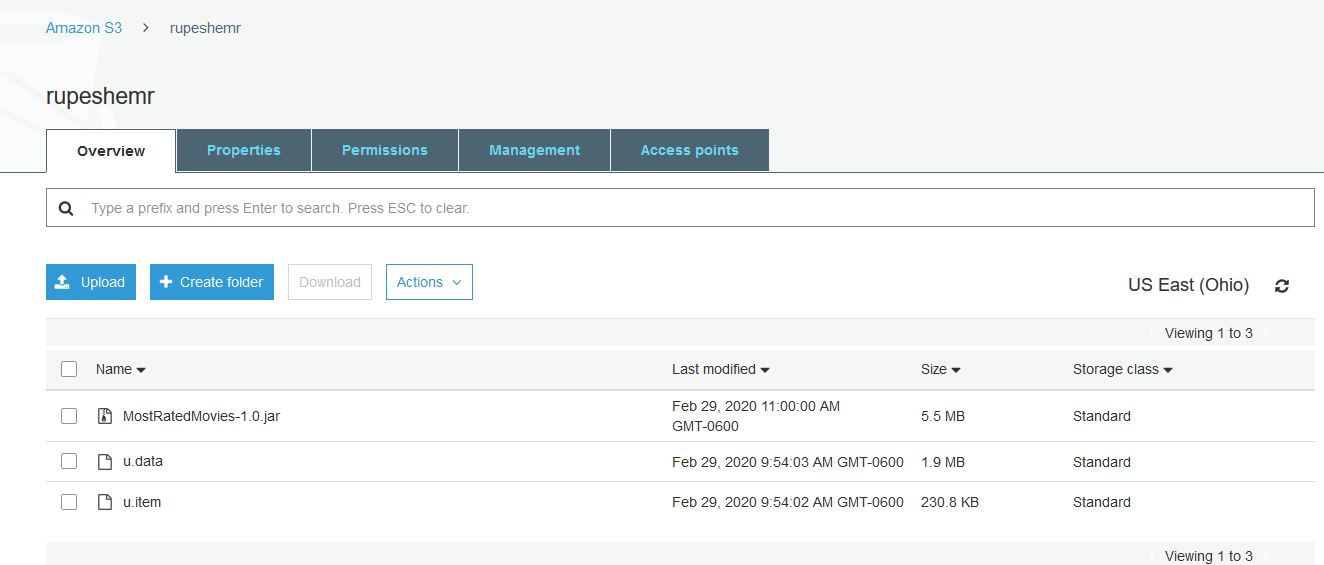
upload the jar files and the data files to s3 bucket .Use UI or below cli commands
-
aws configure aws s3api create-bucket --bucket rupeshemr aws s3 sync data/- Verify the data is uploaded to s3 bucket
-
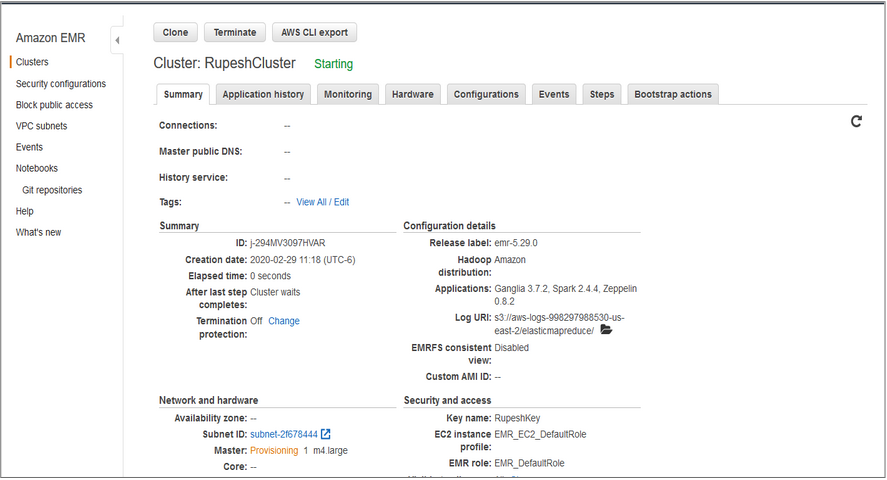
Create an Amazon EMR cluster
-
Step 4
-
Use the aws cli or the UI to create the cluster.
-
aws emr create-cluster \ --instance-type m3.xlarge \ --release-label emr-5.10.0 \ --service-role EMR_DefaultRole \ --ec2-attributes InstanceProfile=EMR_EC2_DefaultRole \ --security-configuration mySecurityConfiguration \ --kerberos-attributes file://kerberos_attributes.json- Verify Cluster Creation
-
-
Step5
- Add SSH Inbound rule to security groups
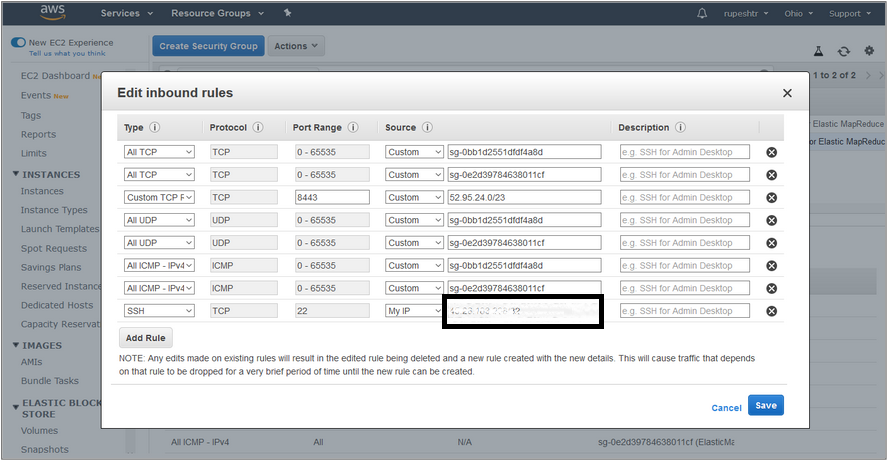
- Step 6
- ssh into emr master node
-
-
Copy your driver program’s JAR file and any other files required.
-
aws s3 cp s3://rupeshemr/Movies-1.0.jar ./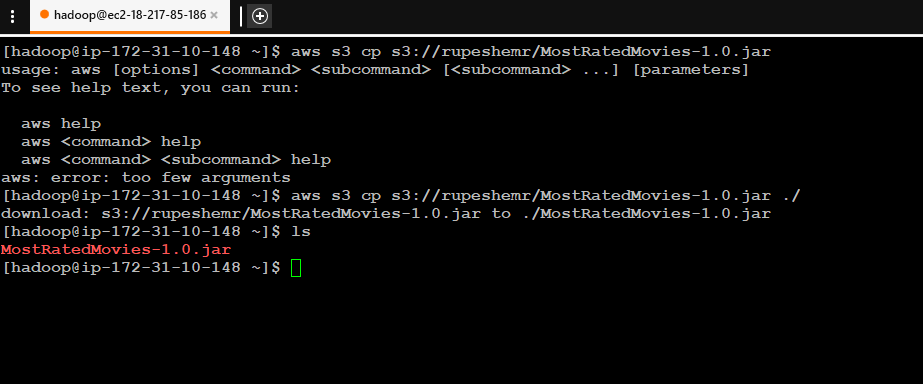
Submit the Spark Job
-
Step 7
-
spark-submit Movies-1.0.jar
-
-
Verify Results of top rated movies
-
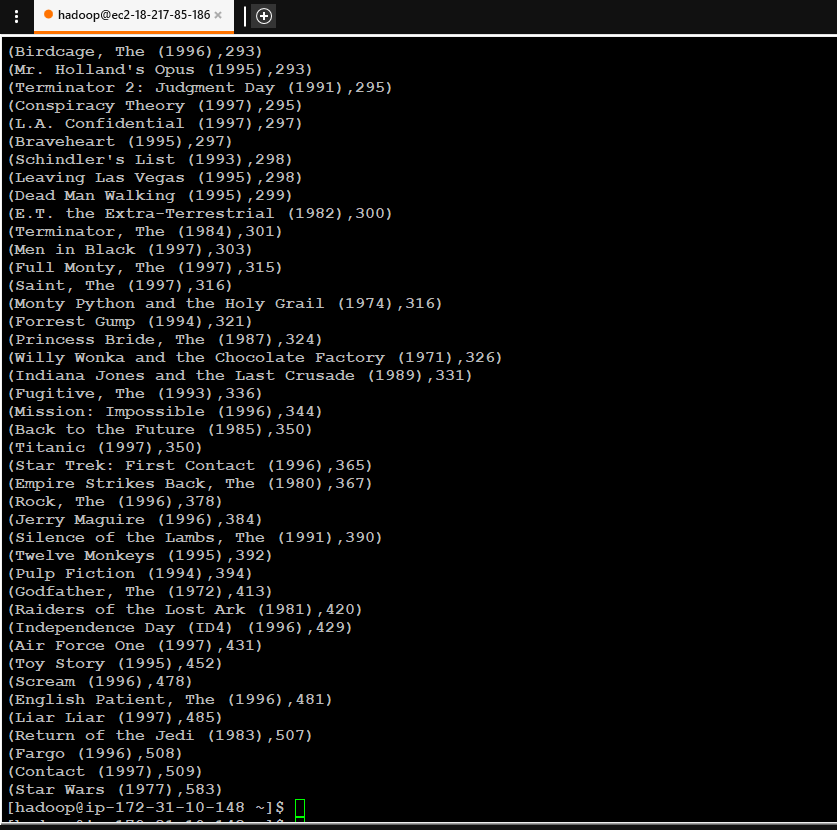
- Use the Spark History Server UI to see the Spark Job History for submitted job
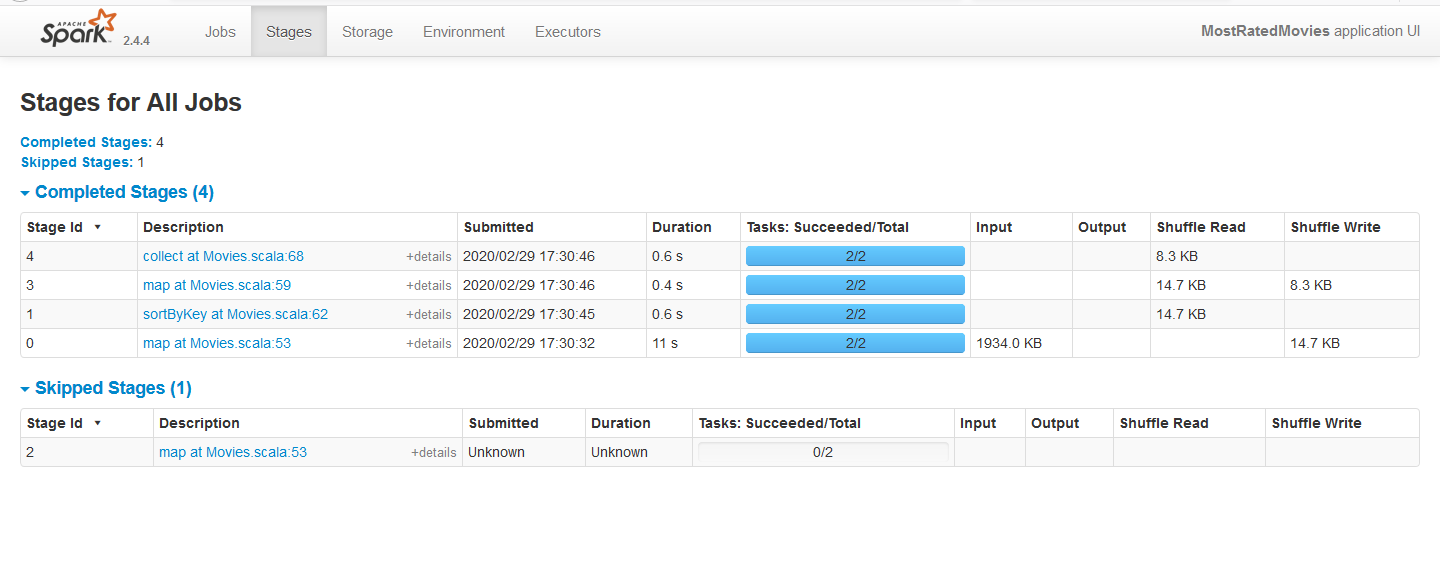
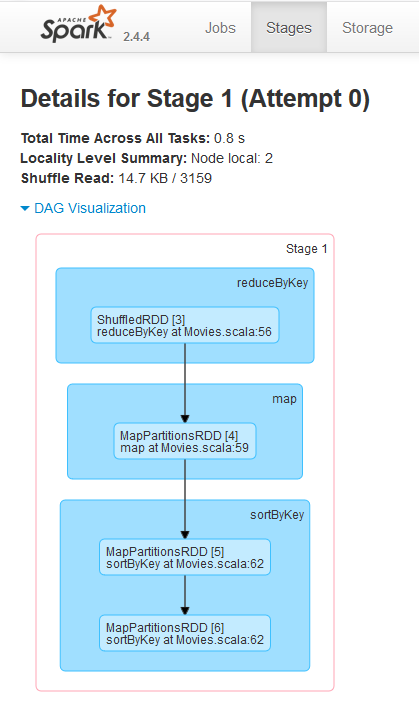
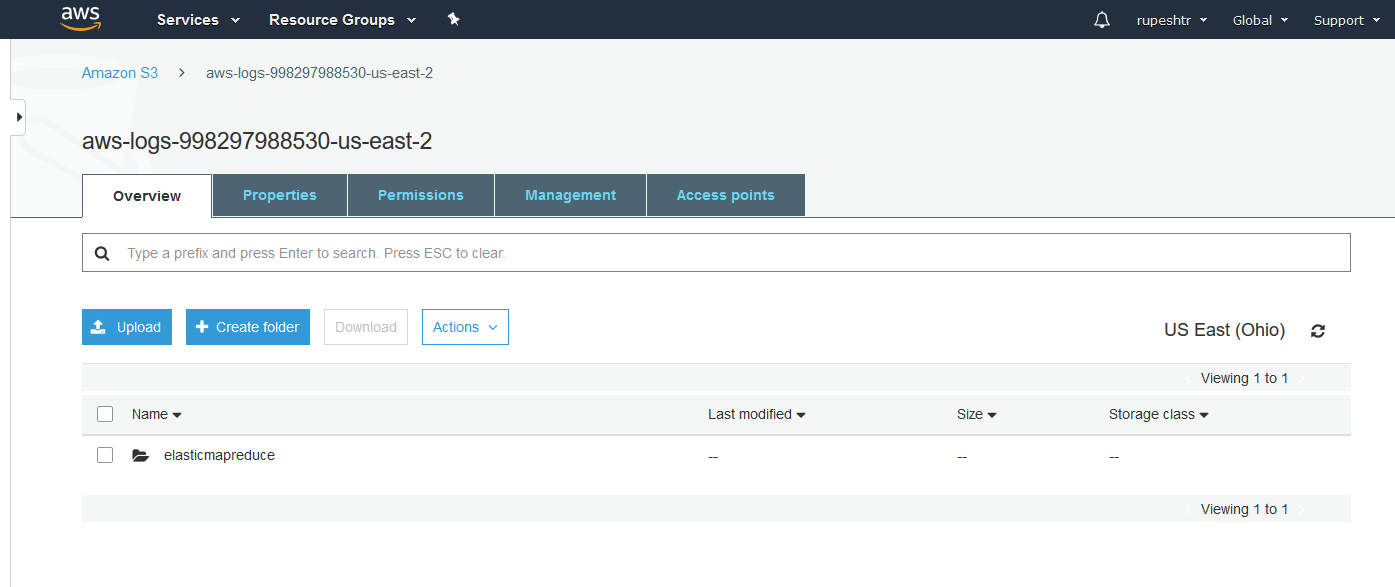
- Verify Amazon s3 bucket for logs created for the job
TERMINATE YOUR CLUSTER WHEN YOU’RE DONE