Elastisearch is a distributed document search and analytics engine, real-time search.
Kibana, paired with elastisearch provises interactive exploration bash board creation and analysis.
Amazon offers an Elasticsearch as Service
In this example we will try to Inject Structured Streaming data in to Elastisearch and visualize the results using Kibana.
Download and unzip elastisearch and Kibana configure the respective yml files in conf directory.
Start Elastisearch and Kibana
./bin/elasticsearch
./bin/kibana
# Verify elastisearch use elastisearch ip and port
curl -X GET "XXX.168.1.XXX:9200/"
Spark
Initialize spark session
val spark = SparkSession.builder()
.appName("Spark Kafka ElastiSearch")
.master("local[*]")
.config("spark.es.nodes","XXX.XXX.1.200")
.config("spark.es.port","9200")
.config("es.index.auto.create", "true")
.getOrCreate()
Read log data from Kafka Stream and Parse the lines.
val regexPatterns = Map(
"ddd" -> "\\d{1,3}".r,
"ip" -> """s"($ddd\\.$ddd\\.$ddd\\.$ddd)?"""".r,
"client" -> "(\\S+)".r,
"user" -> "(\\S+)".r,
"dateTime" -> "(\\[.+?\\])".r,
"datetimeNoBrackets" -> "(?<=\\[).+?(?=\\])".r,
"request" -> "\"(.*?)\"".r,
"status" -> "(\\d{3})".r,
"bytes" -> "(\\S+)".r,
"referer" -> "\"(.*?)\"".r,
"agent" -> """\"(.*)\"""".r
)
def parseLog(regExPattern: String) = udf((url: String) =>
regexPatterns(regExPattern).findFirstIn(url) match
{
case Some(parsedValue) => parsedValue
case None => "unknown"
}
)
// val requestRegex = "(\\S+)"
import spark.implicits._
def parseKafka() ={
readKafka()
.select(col("topic").cast(StringType),
col("offset"),
col("value").cast(StringType))
.withColumn("user", parseLog("user")($"value"))
.withColumn("dateTime", parseLog("datetimeNoBrackets")($"value"))
.withColumn("request", parseLog("request")($"value"))
.withColumn("agent", parseLog("agent")($"value"))
.withColumn("status", parseLog("status")($"agent"))
}
case class LogsData(offset: Double,
status: Double,
user: String,
request: String,
dateTime: Timestamp)
val DATE_FORMAT = "dd/MMM/yyyy:HH:mm:ss ZZZZ"
val dateFormat = new SimpleDateFormat(DATE_FORMAT)
val convertStringToDate2 = udf((dateString: String) =>
new java.sql.Date(dateFormat.parse(dateString).getTime)
)
def parseDate() = {
parseKafka().select(col("offset").cast("double"),
col("status").cast("double"),
col("user"),col("request"),
col("dateTime"))
// to_timestamp(col("dateTime"),"dd/MMM/yyyy:HH:mm:ss ZZZZ").as("to_date"))
.withColumn("dateTime", convertStringToDate2(col("dateTime")))
.as[LogsData]
Write the Dataset Stream to ElastiSearch in batches
def writeKafkaElastiSearch() = {
parseDate()
.writeStream
.foreachBatch { (batch: Dataset[LogsData], batchId: Long) =>
batch.select(col("*"))
.write
.format("org.elasticsearch.spark.sql")
.option("checkpointLocation", "checkpoint")
.mode(SaveMode.Append)
.save("dblkafkastream/dblkafkatype")
}
.start()
.awaitTermination()
}
ElastiSearch
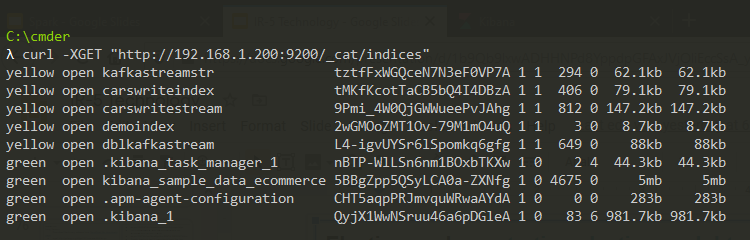
Verify Index creation in Elastisearch
curl -XGET "http://XXX.168.1.XXX:9200/_cat/indices"
Kibana
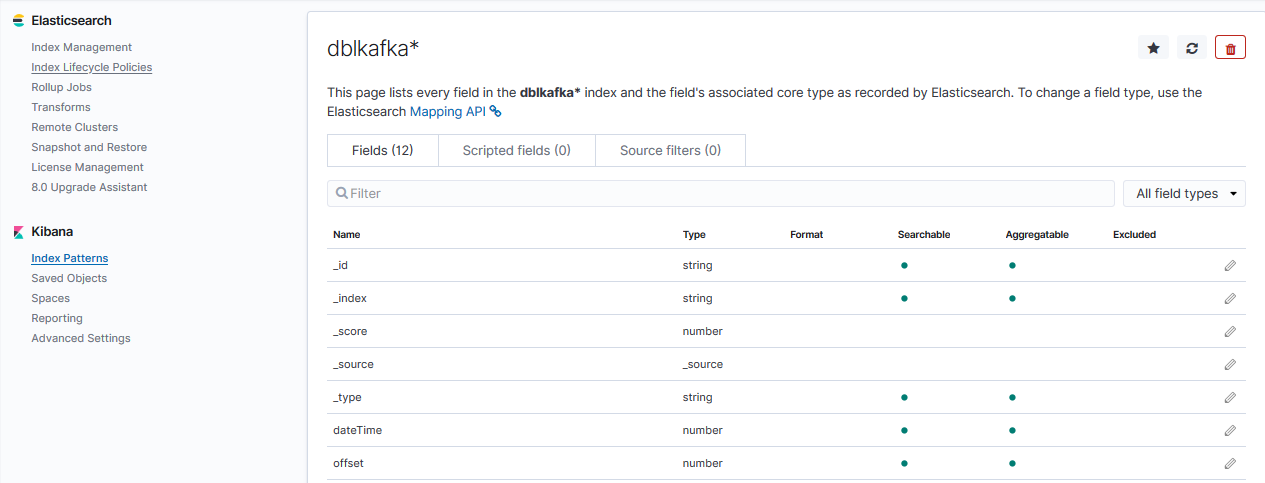
Kibana webUI under Settings Create Index Pattern.
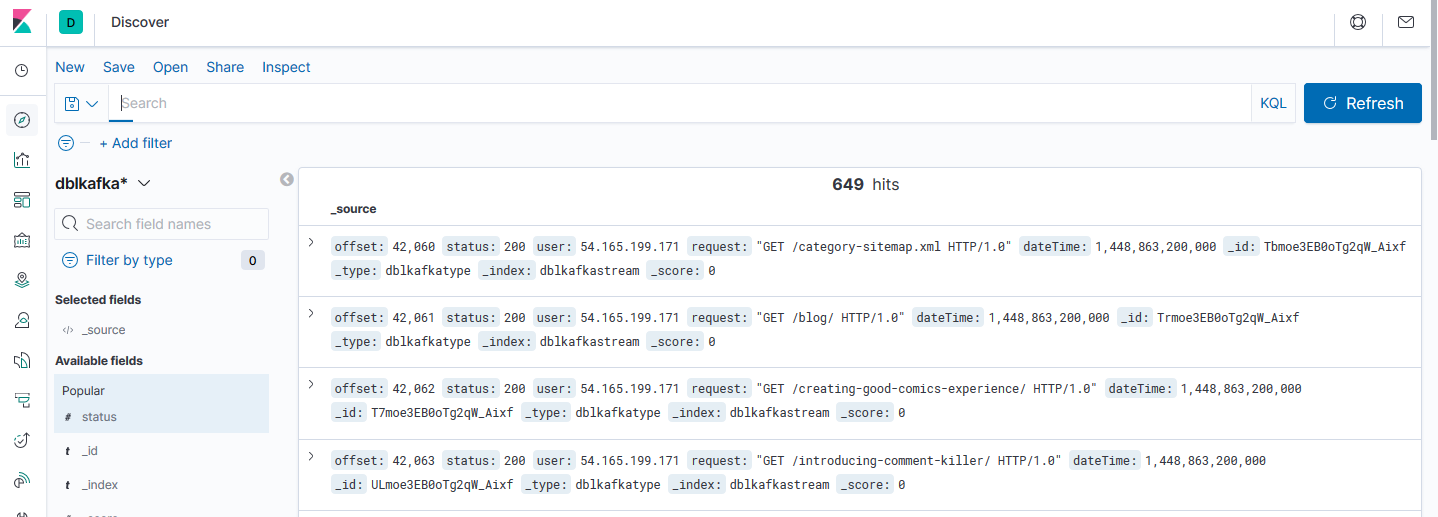
Kibana Discover Tab View the Raw data and verify data injected in real time
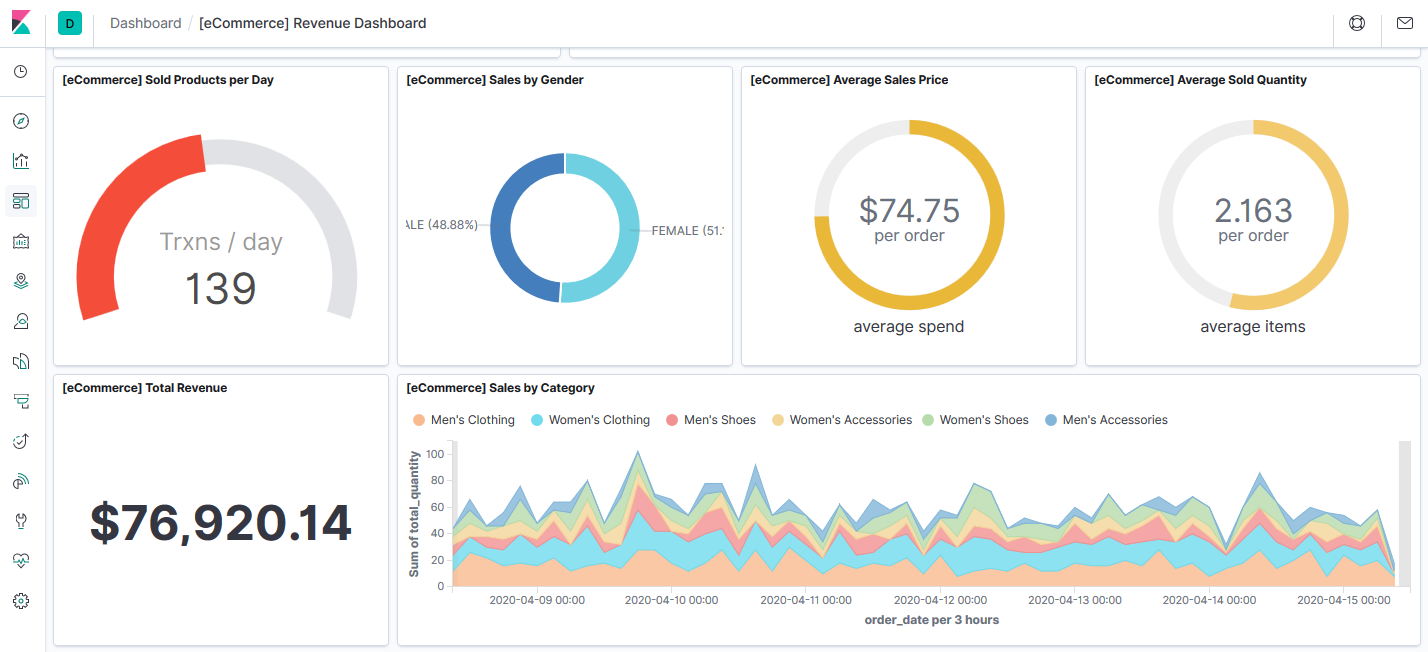
Kibana Real Time Visualization
Visualize extracted error codes from the Web logs and monitor error codes in real time.
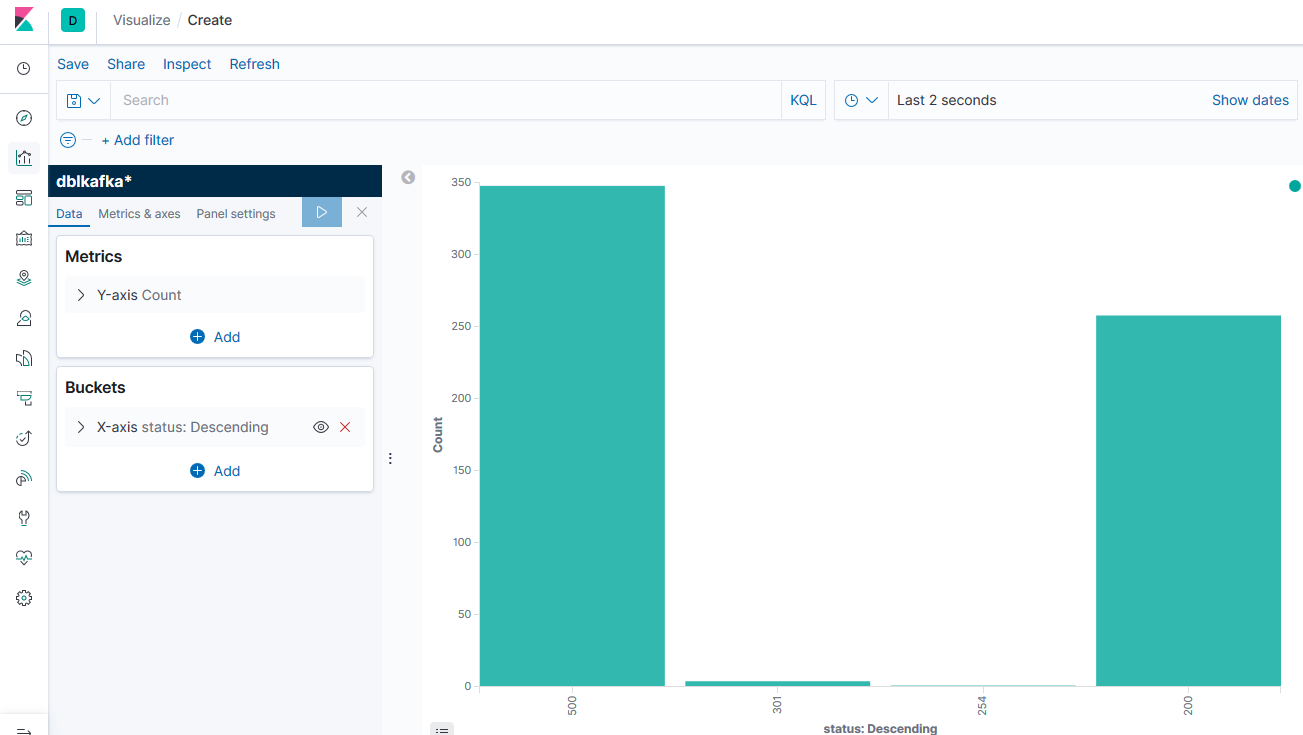
Example of Visualizations in Kibana
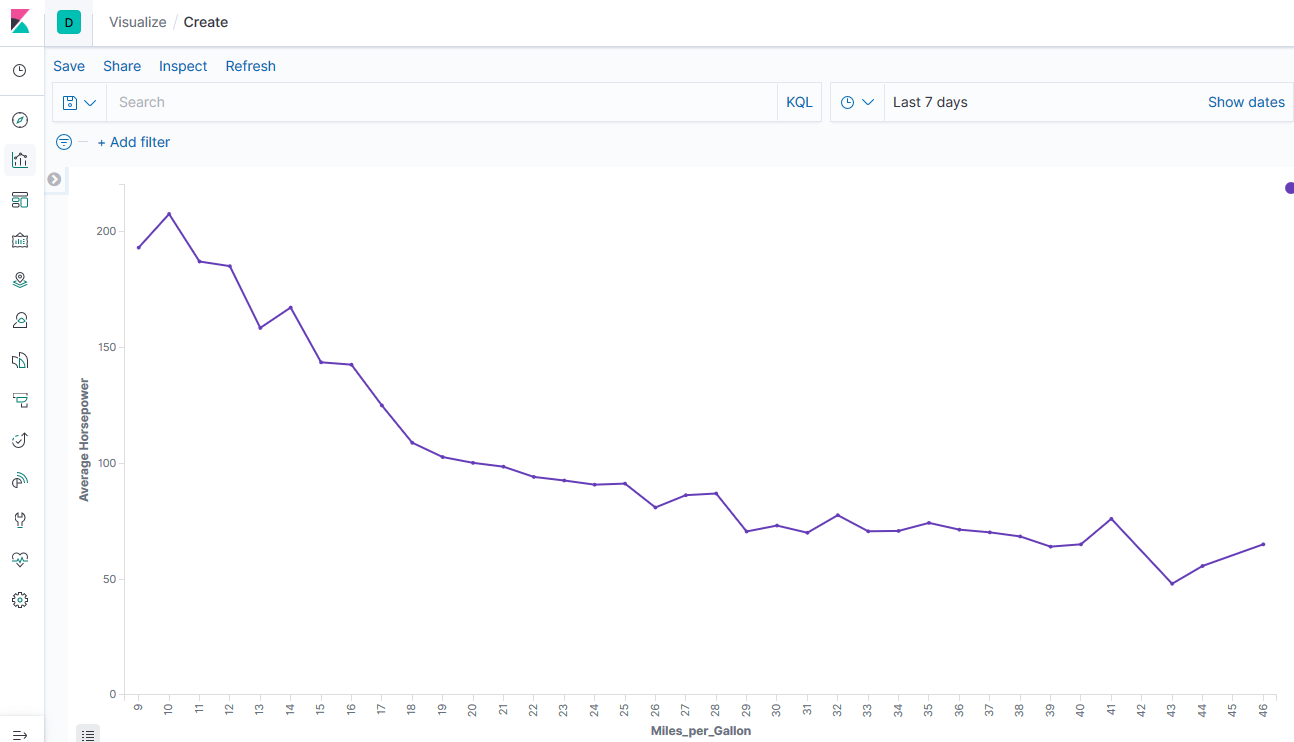
Based on cars data plot of horse power vs MPG
Dependencies
// kafka
"org.apache.kafka" %% "kafka" % kafkaVersion,
"org.apache.kafka" % "kafka-streams" % kafkaVersion,
// streaming-kafka
"org.apache.spark" % "spark-sql-kafka-0-10_2.11" % sparkVersion,
// low-level integrations
"org.apache.spark" %% "spark-streaming-kafka-0-10" % sparkVersion,
"org.elasticsearch" %% "elasticsearch-spark-20" % "7.6.1"