kafka Stream Word Count.
Kafka Streams Key Concepts:
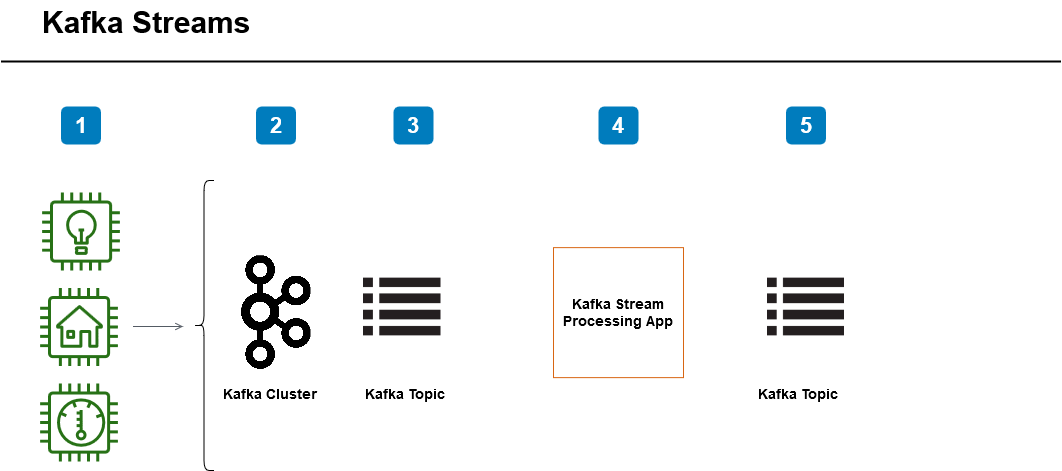
Stream: An ordered, replayable, and fault-tolerant sequence of immutable data records, where each data record is **defined as a **key-value pair.A source processor consumes data from a topic and passes it on to sink processors •
Stream Processor: A node in the processor topology represents a processing step to transform data in streams by receiving one input record at a time from its source in the topology, applying any operation to it, and may subsequently produce one or more output records to its sinks.
There are two individual processors in the topology:
Source Processor: A source processor is a special type of stream processor that does not have any upstream processors. It produces an input stream to its topology from one or multiple Kafka topics by consuming records from these topics and forwarding them to its down-stream processors.
Sink Processor: A sink processor is a special type of stream processor that does not have down-stream processors. It sends any received records from its up-stream processors to a specified Kafka topic.
Stateful vs Stateless
Stateful
Stateful applications and processes,are those that can be returned to again and again, like online banking or email. They’re performed with the context of previous transactions and the current transaction may be affected by what happened during previous transactions.Stateful → If your application requires memory of what happens from one session to the next.
Stateless
Stateless process or application can be understood in isolation. There is no stored knowledge of or reference to past transactions. Each transaction is made as if from scratch for the first time. Independent
Stateless Stateful operations**
Stateless operations, such as **filter and map, retain no state from previously seen element when processing a new element – each element can be processed independently of operations on other elements.
Stateful operations, such as distinct ,avg and sorted, may incorporate state from previously seen elements when processing new elements.
import java.time.Duration
import java.util.Properties
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.Serdes
import org.apache.kafka.streams.{KafkaStreams, KeyValue, StreamsBuilder, StreamsConfig}
import org.apache.kafka.streams.kstream.{KStream, KTable, Materialized, Printed, Produced}
import scala.collection.JavaConverters.asJavaIterableConverter
object kafkaStreamWordCount extends App {
val config: Properties = {
val properties = new Properties()
properties.put(StreamsConfig.APPLICATION_ID_CONFIG, "KStreamApp")
properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.200:9092")
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest")
properties.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG, StreamsConfig.EXACTLY_ONCE)
properties.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName())
properties.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName())
properties
}
val inputTopic = "InputKStreamTopic"
val outputTopic = "OutputKStreamTopic"
// StreamsBuilder provide the high-level Kafka Streams DSL domain-specific language to specify a Kafka Streams topology.
val builder: StreamsBuilder = new StreamsBuilder
// State full Operations@Todo
val textLines: KStream[String, String] = builder.stream[String, String](inputTopic)
val wordKStream: KStream[String, String] = textLines
.flatMapValues{ textLine =>
println(s"Textline= $textLine")
textLine.toLowerCase.split("\\W+").toIterable.asJava
}
// Printed.toSysOut() can be used for debugging
wordKStream.print(Printed.toSysOut())
val wordsMap: KStream[String, String] = wordKStream.map((_,value) => new KeyValue[String,String](value,value))
wordsMap.print(Printed.toSysOut())
val wordsMapGKeyTable: KTable[String,String] = wordsMap.groupByKey().count() .mapValues(value => value.toString())
val wordsCountKStream: KStream[String,String] = wordsMapGKeyTable.toStream()
wordsCountKStream.print(Printed.toSysOut())
// wordsCountKStream.peek((k,v) =>
// {
// val theKey = k
// val theValue =v
// })
// .to(outputTopic)
val stringSerde = Serdes.String
val longSerde = Serdes.Long()
wordsCountKStream.to(outputTopic)
// Produced.`with`(stringSerde,longSerde))
// Start the Streams Application
val kEventStream = new KafkaStreams(builder.build(), config)
kEventStream.start()
sys.ShutdownHookThread {
kEventStream.close(Duration.ofMinutes(20))
}
}
Kstream: KStream is nothing but that, a Kafka Stream. It’s a never-ending flow of data in a stream. Each piece of data — a record or a fact — is a collection of key-value pairs. Data records in a record stream are always interpreted as an “INSERT”.
KStream is an abstraction of a record stream of KeyValue pairs, i.e., each record is an independent entity/event in the real world. For example a user K might buy two items V1 and V2, and thus there might be two records < K,V1 >, < K,V2> in the stream.
KTable: A KTable is just an abstraction of the stream, where only the latest value is kept. Data records in a record stream are always interpreted as an “UPDATE”.
KGroupedStream:If you want to perform stateful aggregations on the contents of a KStream, you’ll first need to group its records by their key to create a KGroupedStream.
Stateless
Stateless process or application can be understood in isolation. There is no stored knowledge of or reference to past transactions. Each transaction is made as if from scratch for the first time. Independent
import java.time.Duration
import java.util.Properties
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.Serdes
import org.apache.kafka.streams.{KafkaStreams, StreamsBuilder, StreamsConfig}
import org.apache.kafka.streams.kstream.{KStream, Printed}
object KafkaStreamStateLess extends App {
val config: Properties = {
val properties = new Properties()
properties.put(StreamsConfig.APPLICATION_ID_CONFIG, "KStreamApp")
properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.131:32770")
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest")
properties.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG, StreamsConfig.EXACTLY_ONCE)
properties.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass)
properties.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass)
properties
}
val inputTopic = "InputKStreamTopic"
val outputTopic = "OutputKStreamTopic"
// StreamsBuilder provide the high-level Kafka Streams DSL domain-specific language to specify a Kafka Streams topology.
val builder: StreamsBuilder = new StreamsBuilder
//Stateless WordStream LowerCase Processing KStream KTable@Todo
val wordStream: KStream[String, String] = builder.stream[String,String](inputTopic)
val lowerWords:KStream[String,String] = wordStream.mapValues((_,words) => words.toLowerCase)
lowerWords.print(Printed.toSysOut())
val filteredWords = lowerWords.filter((_,value) => value !="scala")
// lowerWords.to(outputTopic)
filteredWords.to(outputTopic)
// Starts the Streams Application
val kEventStream = new KafkaStreams(builder.build(), config)
kEventStream.start()
sys.ShutdownHookThread {
kEventStream.close(Duration.ofMinutes(20))
}
}
KafkaProducer uses Serializer - to transform Key and Value to array of bytes, and KafkaConsumer uses Deserializer to transform array of bytes to Key and Value