In this post we will explore Spark SQL reading processing and writing data stored in Apache Hive.
Apache Hive
- Translates SQL queries to MapReduce or Tez jobs on your cluster
- HIve Distributes SQL queries with Hadoop
- Hive can be used for analytical queries while HBase for real-time querying
- Easy OLAP queries – WAY easier than writing MapReduce in Java
- Highly optimized , ■ Highly extensible
-
- – User defined functions
- – Thrift server
- – JDBC / ODBC driver
- Hive maintains a “metastore” that imparts a structure you define on the unstructured data that is stored on HDFS etc
- Hive with spark allows utilization HIve sql functions with spark.
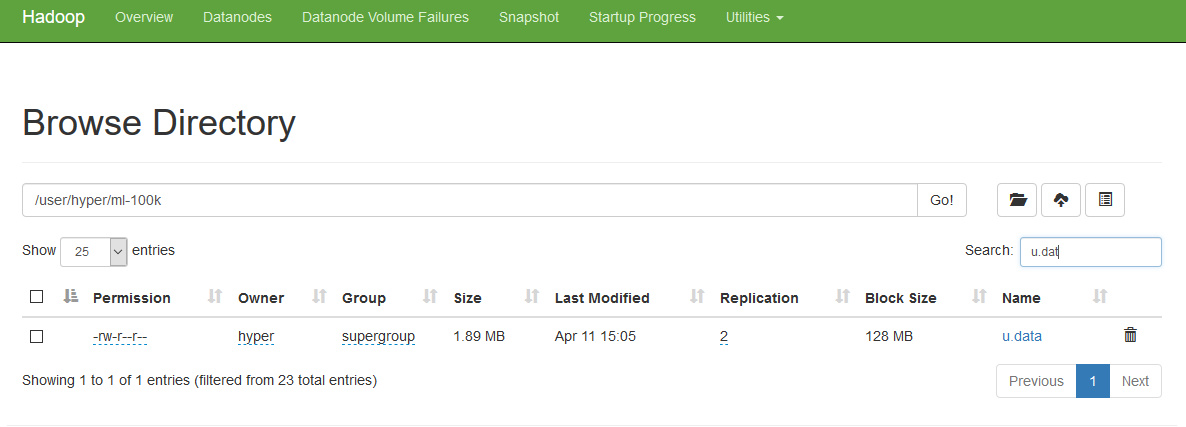
Put the text file to Hadoop File System
val conf = new Configuration()
val hdfsURI = new URI("hdfs://192.168.1.200:9000")
val fs = FileSystem.get(hdfsURI,conf)
def hdfsCopyFromLocal()= {
// * The src file is on the local disk. Add it to FS at
// * the given dst name and the source is kept intact afterwards
val sourcePath = new Path("data/flight-data/csv/2015-summary.csv")
val hdfsDestPath = new Path("/user/hyper/bookdata")
fs.copyFromLocalFile(sourcePath, hdfsDestPath)
}
http://192.168.1.131:9870
Create Spark Session with hive support.
//Enable Hive Support
val hiveWarehousePath = "hdfs://XXX.XXX.XX1.XXX:9000/user/hive/warehouse"
val hiveWarehouse = new File(hiveWarehousePath).getAbsolutePath
val spark = SparkSession.builder()
.appName("Stocks App")
.master("local[*]")
//Option 1 //hive --service metastore
.config("spark.sql.warehouse.dir", hiveWarehouse)
.enableHiveSupport()
.getOrCreate()
//Option 2
.config("hive.metastore.uris","thrift://192.168.1.200:9083/default")
//After Spark Initialization setConf
//Option 3
spark.sqlContext.setConf("hive.metastore.warehouse.dir", hiveWarehouse)
spark.sqlContext.setConf("hive.exec.dynamic.partition.mode", "nonstrict")
spark.sqlContext.setConf("hive.exec.dynamic.partition", "true")
Spark read write from Hive
def hiveSparkBasics() = {
spark.catalog.listDatabases().show(false)
sql("use firstdb;")
// List Tables
spark.catalog.listTables().show(false)
spark.conf.getAll.mkString("\n")
// Drop Tables
// sql(
// """
// |DROP TABLE FLIGHTS_DATA;
// |""".stripMargin)
// Create Tables with properties
sql(
"""
|CREATE TABLE IF NOT EXISTS FLIGHTS_DATA (DEST_COUNTRY_NAME STRING,ORIGIN_COUNTRY_NAME STRING ,count INT)
|ROW FORMAT DELIMITED
|FIELDS TERMINATED BY ','
|LINES TERMINATED BY '\n'
|STORED AS TEXTFILE
|TBLPROPERTIES("skip.header.line.count"='1');
|""".stripMargin)
spark.catalog.listTables().show(false)
// Load Data
sql(
"""
|LOAD DATA LOCAL INPATH 'data/flight-data/csv/2015-summary.csv'
|OVERWRITE INTO TABLE FLIGHTS_DATA
|""".stripMargin)
// Alter Table
sql(
"""
|ALTER TABLE flights_data SET TBLPROPERTIES ("skip.header.line.count"="1");
|""".stripMargin)
// Describe Table
sql(
"""
|describe table extended flights_data ;
|""".stripMargin)
}
// Spark Hive Read Write
def hiveReadWrite() ={
// Create table using DataFrame API
sql("use firstdb;")
val flightsDFSql = sql(
"""
|select * from flights_data where ORIGIN_COUNTRY_NAME="United States";
|""".stripMargin)
val flightsTableDF = spark.table("flights_data")
flightsTableDF
.filter(col("ORIGIN_COUNTRY_NAME") === "United States")
.write.mode(SaveMode.Overwrite)
.saveAsTable("spark_us_flights")
spark.catalog.listTables().show()
}
Partitioning Bucketing Using DataFrame API
// Use Partitions and Bucketing
def hivePartitions() = {
sql(s"use firstdb")
val dataDir = "hdfs://192.168.1.200:9000/user/hyper/bookdata/parquet"
spark.range(1000).write.parquet(dataDir)
sql(s"CREATE TABLE IF NOT EXISTS big_int_parquet(id bigint) STORED AS PARQUET LOCATION '$dataDir';")
// spark.catalog.listTables().show()
val numDF = spark.table("big_int_parquet")
numDF.persist(StorageLevel.MEMORY_AND_DISK)
val pairSchema = StructType(numDF.schema.fields ++ Array(StructField("rowId",LongType)))
// Create Key Value DF
val zipIndexRDD = numDF.rdd.zipWithIndex()
zipIndexRDD.persist(StorageLevel.MEMORY_AND_DISK)
val zipMapRDD = zipIndexRDD.map(row => (row._2,row._1.getLong(0)))
val kvDF = zipMapRDD.toDF("id","value")
// kvDF.show()
// Turn on flag for Hive Dynamic Partitioning
spark.sqlContext.setConf("hive.exec.dynamic.partition", "true")
spark.sqlContext.setConf("hive.exec.dynamic.partition.mode", "nonstrict")
// Create a Hive partitioned table using DataFrame API
kvDF.write
// .partitionBy("id")
.bucketBy(20,"id")
.format("parquet") //format("csv") // format("hive)
.saveAsTable("hive_buckets_tbl")
// Partitioned column `key` will be moved to the end of the schema.
sql("SELECT * FROM hive_buckets_tbl").show()
}
// OverWrite Append Insert
def hiveInsertAppend() = {
sql(s"use firstdb")
Seq((1, 2)).toDF("i", "j").write.mode("overwrite").saveAsTable("append_table")
Seq((3, 4)).toDF("j", "i").write.mode("append").saveAsTable("append_table")
// overwrites old data with new
Seq((1,5)).toDF("i","j")
.write.mode("overwrite").saveAsTable("append_table")
/*
+---+---+
| i| j|
+---+---+
| 1| 5|
+---+---+
*/
// append
Seq((1,6)).toDF("i","j")
.write.mode("append")
.saveAsTable("append_table")
/*
+---+---+
| i| j|
+---+---+
| 1| 5|
| 1| 6|
+---+---+
*/
// insert into
Seq((1,5)).toDF("i","j")
.write
.insertInto("append_table")
/*
+---+---+
| i| j|
+---+---+
| 1| 5|
| 1| 5|
| 1| 7|
| 1| 6|
+---+---+
*/
sql(s"select * from append_table").show()
}
Hive UTDF :- User Defined Table Generating Function
def hiveUTDF() = {
val carSeq = Seq(
("chevrolet chevelle malibu",Array(18.0,8L,307.0,130L,3504L,12.0),"1970-01-01","USA"),
("buick skylark 320",Array(15.0,8L,350.0,165L,3693L,11.5),"1970-01-01","USA"),
("plymouth satellite",Array(18.0,8L,318.0,150L,3436L,11.0),"1970-01-01","USA"),
("amc rebel sst",Array(16.0,8L,304.0,150L,3433L,12.0),"1970-01-01","USA")
)
carSeq.toDF("name","specs","year","country").write.mode(SaveMode.Overwrite).saveAsTable("cars_table")
// Explode
sql(s"select name, explode(specs) from cars_table;")
sql(
"""
|select name,specs,specs_view from cars_table
|lateral view explode(specs) specs_view as specs_view;
|""".stripMargin)
/*
+--------------------+--------------------+----------+
| name | specs|specs_view|
+--------------------+--------------------+----------+
|chevrolet chevell...|[18.0, 8.0, 307.0...| 18.0|
|chevrolet chevell...|[18.0, 8.0, 307.0...| 8.0|
|chevrolet chevell...|[18.0, 8.0, 307.0...| 307.0|
|chevrolet chevell...|[18.0, 8.0, 307.0...| 130.0|
|chevrolet chevell...|[18.0, 8.0, 307.0...| 3504.0|
|chevrolet chevell...|[18.0, 8.0, 307.0...| 12.0|
*/
//posexplode
sql(
"""
|select name , posexplode(specs) from cars_table;
|""".stripMargin)
/*
+--------------------+---+------+
| name|pos| col|
+--------------------+---+------+
|chevrolet chevell...| 0| 18.0|
|chevrolet chevell...| 1| 8.0|
|chevrolet chevell...| 2| 307.0|
|chevrolet chevell...| 3| 130.0|
|chevrolet chevell...| 4|3504.0|
|chevrolet chevell...| 5| 12.0|
*/
sql(
"""
|select name , specs[0] as MPG , specs[1] as cylinders , specs[3] as hp from cars_table;
|""".stripMargin)
/*
+--------------------+----+---------+-----+
| name| MPG|cylinders| hp|
+--------------------+----+---------+-----+
|chevrolet chevell...|18.0| 8.0|130.0|
| plymouth satellite|18.0| 8.0|150.0|
| buick skylark 320|15.0| 8.0|165.0|
| amc rebel sst|16.0| 8.0|150.0|
+--------------------+----+---------+-----+
*/
Arrays and Maps Data Structure
//chevrolet#chevelle malibu,mpg:15.0#cylinders:6#horsepower:130,1970-01-01,USA
//buick#skylark 320,mpg:12.0#cylinders:8#horsepower:165,1970-01-01,USA
//plymouth#satellite,mpg:18.0#cylinders:6#horsepower:150,1970-01-01,USA
//amc#rebel sst,mpg:16.0#cylinders:6#horsepower:140,1970-01-01,USA
// Arrays and Maps Data Structure
sql(
"""
|create table if not exists cars_map(cars struct<brand:string,model:string>,
|specs map<string,string>, modelyear string,origin string)
|row format delimited
|fields terminated by ','
|collection items terminated by '#'
|map keys terminated by ':';
|""".stripMargin)
sql(
"""
|load data local inpath 'data/cars/cars.txt' overwrite into table cars_map;
|""".stripMargin)
sql(
"""
|select cars.brand,cars.model,specs["mpg"] as mpg , specs["cylinders"] as mpg,specs["horsepower"] as mpg,
|modelyear, origin from cars_map;
|""".stripMargin)
/*
+---------+---------------+----+---+---+----------+------+
| brand| model| mpg|mpg|mpg| modelyear|origin|
+---------+---------------+----+---+---+----------+------+
|chevrolet|chevelle malibu|15.0| 6|130|1970-01-01| USA|
| buick| skylark 320|12.0| 8|165|1970-01-01| USA|
| plymouth| satellite|18.0| 6|150|1970-01-01| USA|
| amc| rebel sst|16.0| 6|140|1970-01-01| USA|
+---------+---------------+----+---+---+----------+------+
*/
}
Nested Json
Process Nested json using Spark and Hive
Create Schema based on json structure
/*
root
|-- CarsSpecs: struct (nullable = true)
| |-- cars: array (nullable = true)
| | |-- element: struct (containsNull = true)
| | | |-- Acceleration: double (nullable = true)
| | | |-- Cylinders: long (nullable = true)
| | | |-- Displacement: long (nullable = true)
| | | |-- Horsepower: long (nullable = true)
| | | |-- Miles_per_Gallon: long (nullable = true)
| | | |-- Name: string (nullable = true)
| | | |-- Origin: string (nullable = true)
| | | |-- Weight_in_lbs: long (nullable = true)
| | | |-- Year: string (nullable = true)
*/
Print Schema of Json First and then map to schema per below.
val carsSchema = new StructType()
.add("CarsSpecs",
new StructType()
.add("cars",
ArrayType(
new StructType()
.add("Name", StringType)
.add("Miles_per_Gallon", IntegerType)
.add("Cylinders", StringType)
.add("Displacement", StringType)
.add("Horsepower", StringType)
.add("Weight_in_lbs", StringType)
.add("Acceleration", StringType)
.add("Year", StringType)
.add("Origin", StringType)
)
)
)
Process the json in spark and write to hive
def nestedJson() = {
val carsJsonDF = spark.read
.option("multiline", "true")
.schema(carsSchema)
.json("hdfs://192.168.1.200:9000/user/hyper/cars/specs.json")
// carsDf.printSchema()
carsJsonDF.show(false)
val carsSpecDF = carsJsonDF.select(col("CarsSpecs").getField("cars").as("carDetails"))
val explodedDF = carsSpecDF.select(explode(col("carDetails")))
val carsDF = explodedDF.select(col("col.*"))
carsDF.write.mode(SaveMode.Overwrite).saveAsTable("cars_json_table")
sql(s"select * from cars_json_table;").show()
}
+--------------------+----------------+---------+------------+----------+-------------+------------+--------
Name |Miles_per_Gallon|Cylinders|Displacement|Horsepower|Weight_in_lbs|Acceleration| Year|Origin|
+--------------------+----------------+---------+------------+----------+-------------+------------+----------+------+
|chevrolet chevell...| 18 |8 | 307| 130| 3504| 12.0|01-01-1970| USA|
|buick skylark 320| 15| 8| 350| 165| 3693| 11.5|01-01-1970| USA|
+--------------------+----------------+---------+------------+----------+-------------+------------+--------
Using Inline UTDF
Inline :- Explodes an array of structs alternate way than using explode UTDF on array of struct.
val carsJsonDF = spark.read
.option("multiline", "true")
.schema(carsSchema)
.json("data/cars/device.json")
// carsDf.printSchema()
carsJsonDF.show(false)
val carsSpecDF = carsJsonDF.select(col("CarsSpecs").getField("cars").as("CarDetails"))
carsSpecDF.createOrReplaceTempView("cars_view")
sql(
"""
|select inline(CarDetails) from cars_view;
|""".stripMargin).show(false)
Min By Max By Stack Functions
Spark 3 allows recursive reading from directories with new option.
val df = spark.createDataFrame(Seq(
("1", 10),
("2", 20),
("3", 30),
("4", 40)
)).toDF("id","value")
df.createOrReplaceTempView("table")
// max_by and min_by functions
// functions take two parameters.
// The first parameter is minimum/maximum we want to find and
// second parameter the value on which we want to find
// id of max value is 4
// id of min value is 1
spark.sql("select max_by(id,value) max_id, min_by(id,value) min_id from table").show(false)
+------+------+
|max_id|min_id|
+------+------+
|4 |1 |
+------+------+
//recursive reading
val recursiveDf = spark.read
.option("delimiter","||")
.option("recursiveFileLookup","true")
.option("header","true")
.csv("data/nested")
assert(recursiveDf.count() == 4)
recursiveDf.show(false)
+---+---+---+---+
|a |b |c |d |
+---+---+---+---+
|1 |2 |3 |4 |
|5 |6 |7 |8 |
|1 |2 |3 |4 |
|5 |6 |7 |8 |
+---+---+---+---+
//stack function
recursiveDf.createOrReplaceTempView("nested_stack")
spark.sql(
"""
|select stack(2,a,b,c,d) from nested_stack;
|""".stripMargin).show(false)
//stack
+----+----+
|col0|col1|
+----+----+
|1 |2 |
|3 |4 |
|5 |6 |
|7 |8 |
|1 |2 |
|3 |4 |
|5 |6 |
|7 |8 |
+----+----+
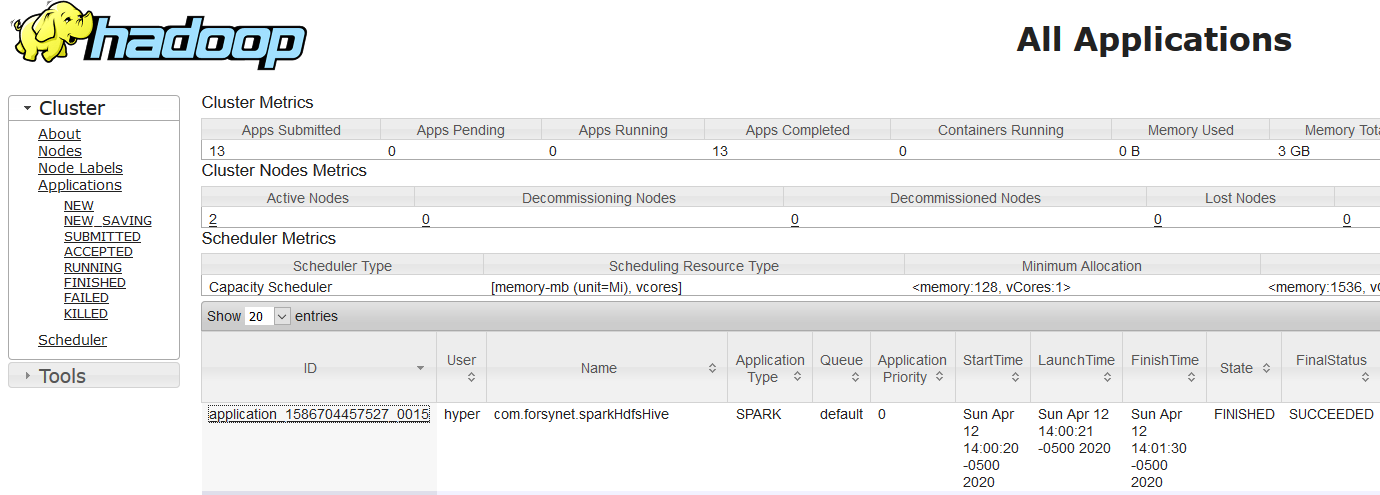
Spark-submit using yarn master
spark-submit \
--class com.forsynet.sparkHdfsHive \
--master yarn \
--deploy-mode cluster \
sparkhdfshive_2.12-0.1.jar
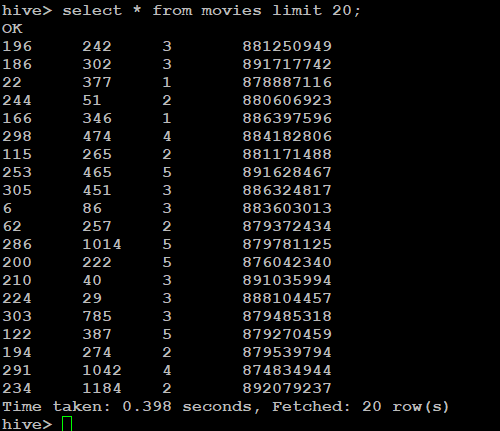
Verify table creation in hive .
hive/bin/hive
hive> select * from movies limit 20;
hive> describe movies;
OK
userid bigint
movieid bigint
rating int
date string
Time taken: 0.136 seconds, Fetched: 4 row(s)
Verify Count of Records in HDFS
val readHiveFiles = spark.read
.load("hdfs://192.168.1.200:9000/user/hive/warehouse/firstDB/hive_buckets_tbl")
.count()
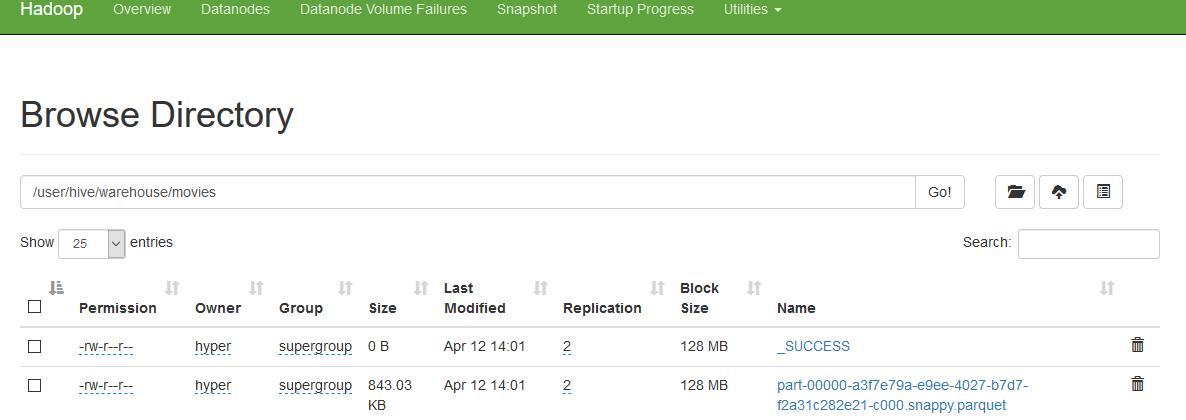
Verify hive warehouse for file creation.
hdfs://node-master:9000/user/hive/warehouse
hyper@node-master:~/spark/$ hdfs dfs -ls /user/hive/warehouse/movies
Found 2 items
-rw-r--r-- 2 hyper supergroup 0 2020-04-12 14:01 /user/hive/warehouse/movies/_SUCCESS
-rw-r--r-- 2 hyper supergroup 863266 2020-04-12 14:01 /user/hive/warehouse/movies/part-00000-a3f7e79a-e9ee-4027-b7d7-f2a31c282e21-c000.snappy.parquet
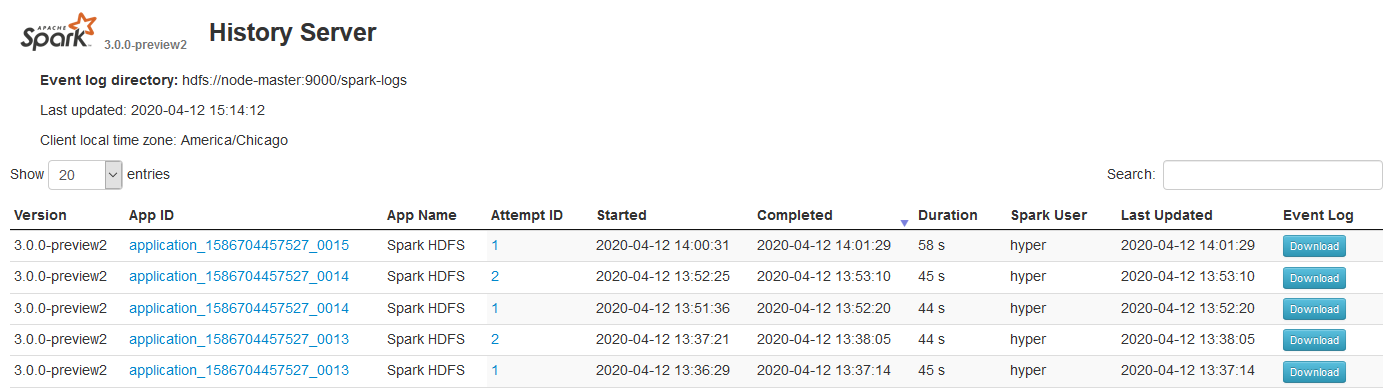
Spark History Server
## Start Spark history server
spark/sbin/start-history-server.sh
Specify the sparkconf required for history server in spark-defaults.conf file
spark.history.provider org.apache.spark.deploy.history.FsHistoryProvider
spark.history.fs.logDirectory hdfs://node-master:9000/spark-logs
spark.history.fs.update.interval 10s
spark.history.ui.port 18080
Hive Start Commands
## Start Hive services
hive/bin hive
hive --service hiveserver2 --hiveconf hive.server2.thrift.port=10001 --hiveconf hive.root.logger=INFO,console --hiveconf hive.server2.thrift.bind.host=192.168.1.131
hive --service metastore