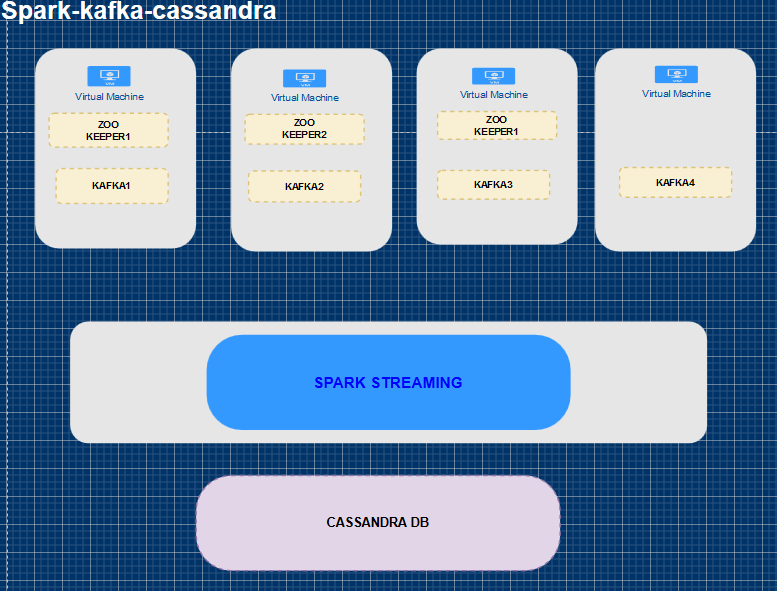
Kafka Streams integrated with Cassandra Sink using Spark Structured Streaming.
Stream apache webserver logs from Kafka, parse the results using Spark Structured streaming and save the parsed results to Cassandra DB as a table. Also write the results to kafka input stream.
- Configure 3 Zookeeper nodes and 4 kafka Brokers.
- Configure Cassandra DB.
- Configure Spark.
Start Zookeeper and Kafka Brokers on the nodes.
kafka/bin/zookeeper-server-start.sh kafka/config/zookeeper.properties
kafka/bin/kafka-server-start.sh kafka/config/server.properties
Create Kafka Topic
kafka/bin/kafka-topics.sh --create --zookeeper XXX.168.1.XXX:2181 \
--replication-factor 3 --partitions 1 \
--topic streams-spark-input3
Verify Topics Using kafka Tool
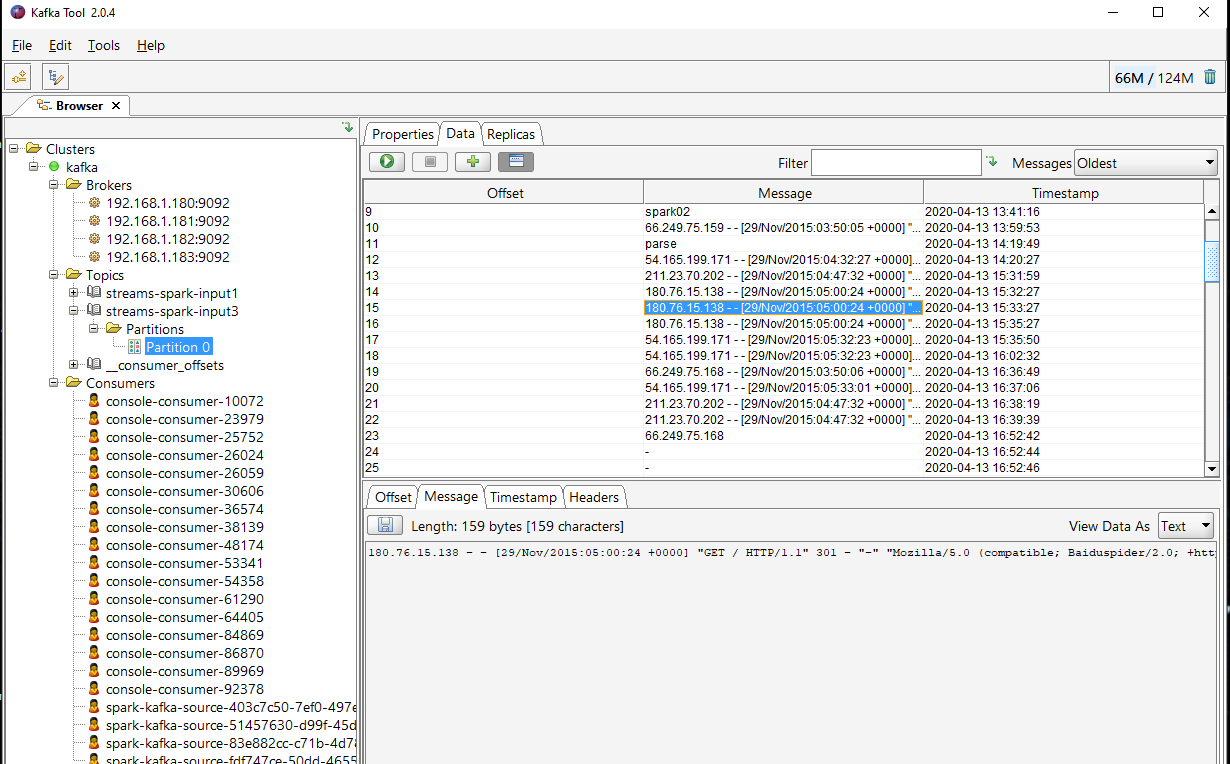
Kafka Producer
To simulate streaming of access-log data we will use the shell script to Pipe the log file line by line to kafka Producer.
while IFS= read -r line; do echo $line && sleep 1; done < \
/home/hyper/data/access_log.txt |\
kafka/bin/kafka-console-producer.sh --broker-list\
192.168.1.181:9092,192.168.1.182:9092,192.168.1.182:9092 --topic streams-spark-input3
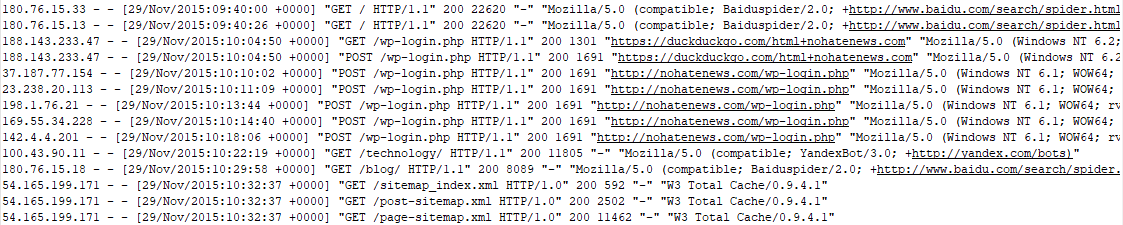
Spark Structured Streaming
Create Spark Session with Cassandra Options.
val spark = SparkSession.builder()
.appName("Spark Kafka Stream")
.master("local[*]")
.config("spark.cassandra.connection.host","XXX.XXX.1.200")
.config("spark.cassandra.connection.port","9042")
.config("spark.cassandra.auth.username","cassandra")
.config("spark.cassandra.auth.password","cassandra")
.getOrCreate()
Read Stream from Kafka from a partition
def readKafka() ={
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers","192.168.1.181:9092")
// .option("subscribe","streams-spark-input")
.option("assign", "{\"streams-spark-input3\":[0]}")
.load()
}
RegEx Function to parse log file data
val regexPatterns = Map(
"ddd" -> "\\d{1,3}".r,
"ip" -> """s"($ddd\\.$ddd\\.$ddd\\.$ddd)?"""".r,
"client" -> "(\\S+)".r,
"user" -> "(\\S+)".r,
"dateTime" -> "(\\[.+?\\])".r,
"datetimeNoBrackets" -> "(?<=\\[).+?(?=\\])".r,
"request" -> "\"(.*?)\"".r,
"status" -> "(\\d{3})".r,
"bytes" -> "(\\S+)".r,
"referer" -> "\"(.*?)\"".r,
"agent" -> """\"(.*)\"""".r
)
// "agent" -> "\"(.*?)\"".r
def parseLog(regExPattern: String) = udf((url: String) =>
regexPatterns(regExPattern).findFirstIn(url) match
{
case Some(parsedValue) => parsedValue
case None => "unknown"
}
)
Parse the Log Files
import spark.implicits._
def parseKafka() ={
readKafka()
.select(col("topic").cast(StringType),
col("offset"),
col("value").cast(StringType))
// .withColumn("client",regexp_extract(col("value"),requestRegex,0))
.withColumn("user", parseLog("user")($"value"))
.withColumn("dateTime", parseLog("datetimeNoBrackets")($"value"))
.withColumn("request", parseLog("request")($"value"))
.withColumn("agent", parseLog("agent")($"value"))
.withColumn("status", parseLog("status")($"agent"))
}
Create Key space and Table in Cassandra DB
cqlsh
cqlsh:hyper> create table hyper.kafkalogsdate("offset" text primary key , "status" text, "user" text,"request" text ,"dateTime" timestamp );
Write to Cassandra DB in batches.
case class logsData(offset: BigInt,
status: String,
user: String,
request: String,
dateTime: Timestamp)
def writeToCassandra(): Unit = {
parseDate().select(col("offset"), col("status"),
col("user"),col("request"),
col("dateTime"))
.as[logsData]
.writeStream
.foreachBatch { (batch: Dataset[logsDate], batchId: Long) =>
batch.select(col("*"))
.write
.cassandraFormat("kafkalogsdate", "hyper")
.mode(SaveMode.Append)
.save()
}
.start()
.awaitTermination()
}
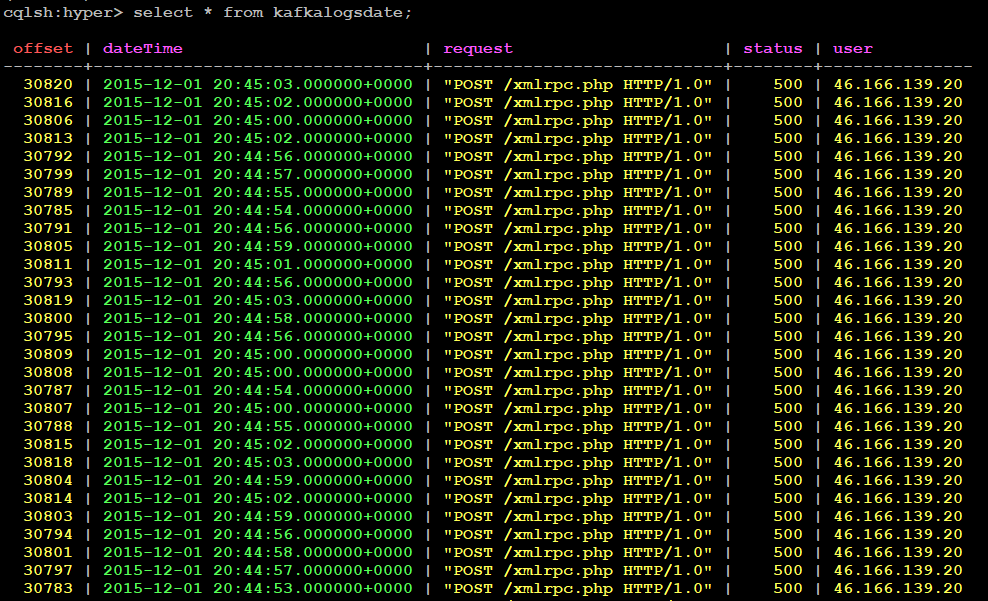
Verify Data in Cassandra DB
cqlsh:hyper> select * from kafkalogsdate;
Write to kafka
Create output Topic
kafka/bin/kafka-topics.sh --create --zookeeper 192.168.1.181:2181 \
--replication-factor 3 --partitions 1 \
--topic streams-spark-output
Spark Write to Kafka.
Kafka needs input stream as key value pairs.
def writeToKafka(): Unit ={
parseDate().select(
col("offset").cast("String").as("key"),
to_json(struct(col("*"))).as("value")
)
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers","192.168.1.181:9092")
.option("topic","streams-spark-output")
.option("checkpointLocation","checkpoint") // without check point program fails
.start()
.awaitTermination()
}
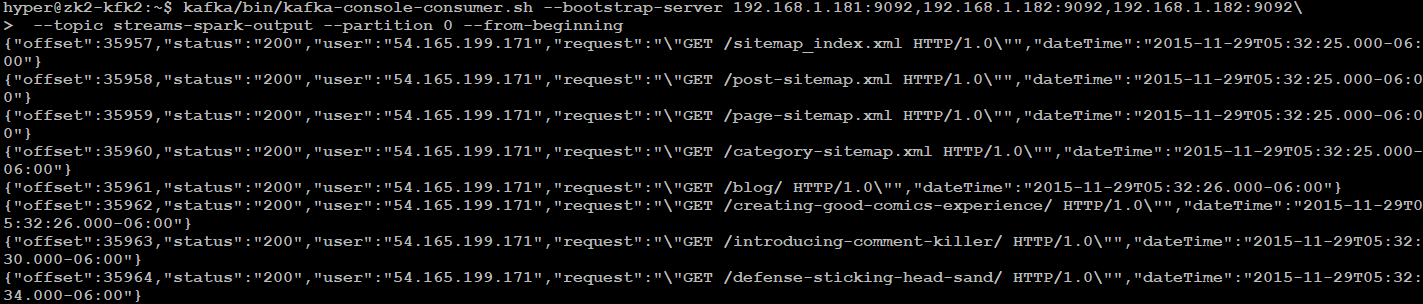
Verify the stream using kafka console consumer.
kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.1.181:9092,192.168.1.182:9092,192.168.1.182:9092\
--topic streams-spark-output --partition 0 --from-beginning