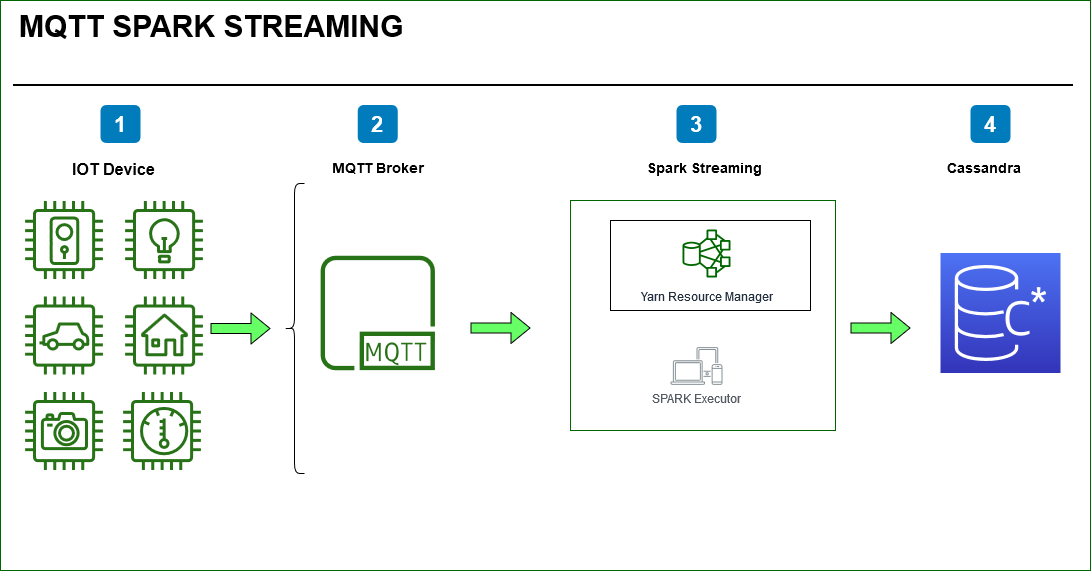
Earlier we created a IOT Device / MQTT Client using Raspberry Pi. We published a message from the device with a simple push button switch to simulate an event using bread board connected to the Pi device.
We will create a Spark Structured Streaming application which will read the published MQTT topic and related messages into spark stream .Using Spark we will parse the log data ,count the status field in the MQTT message by applying Spark window functions and watermark on the IOT timestamp field.
Finally we will write the stream of data to Cassandra sink.
In order to read structured streaming from MQTT we will use data source API for MQTT using this package
org.apache.bahir:spark-sql-streaming-mqtt_2.11:2.4.0
From my understanding Data source works with high level API’s like Data frames and Datasets. Receiver API is for low level DStreams.
Read MQTT Topic from Broker
def readMqttLogs() = {
val lines = spark.readStream
.format("org.apache.bahir.sql.streaming.mqtt.MQTTStreamSourceProvider")
.option("topic", "rupesh/gpiotopic")
.option("persistence", "memory")
.option("cleanSession", "true")
.load("tcp://192.168.1.200:8883")
.selectExpr("CAST(payload AS STRING)").as[String]
Spark WaterMark and Window Operation
Use the timestamp field in the MQTT payload to apply the streaming aggregations.
def mqttWindows()= {
val iotLogStatusDF = MqttGpioSpark.readMqttLogs()
iotLogStatusDF
.withWatermark("iottimestamp","2 minute")
.groupBy(col("status"), window(col("iottimestamp"), "1 minute").as("time_window"))
.agg(count("status").as("Status_Count"))
.select(
col("time_window").getField("start").as("Start"),
col("time_window").getField("end").as("End"),
col("status").as("Status"),
col("Status_Count")
)
}
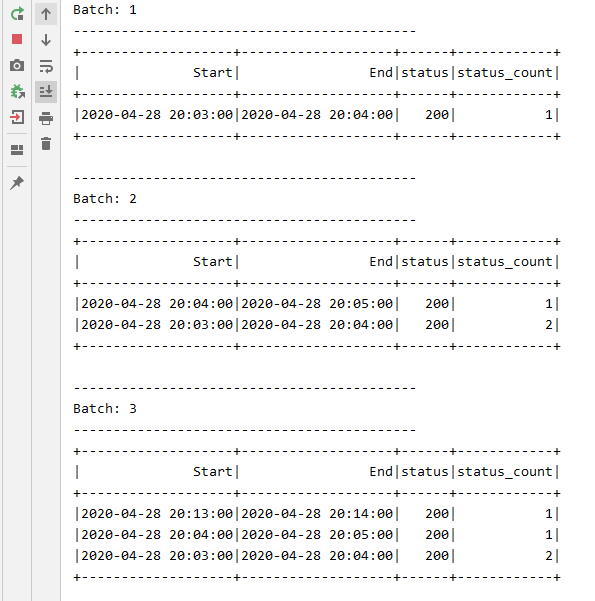
Write the Stream Data after transformations into Cassandra Sink in batches.
def writeToCassandraForEach(): Unit = {
mqttWindowDF
.writeStream
.foreachBatch { (batchDF: DataFrame, batchID: Long) =>
batchDF.write
.format("org.apache.spark.sql.cassandra")
.options(Map("table" -> "mqtt", "keyspace" -> "hyper"))
.mode(SaveMode.Append)
.save
}
.start()
.awaitTermination()
}
Package the applications using Maven mvn clean , compile , package and Deploy on yarn cluster.
./bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--packages org.apache.bahir:spark-sql-streaming-mqtt_2.11:2.4.0,com.datastax.spark:spark-cassandra-connector_2.11:2.4.2 \
--class org.forsynet.mqttgpio.MqttCassandraSink \
--verbose \
/home/hyper/spark/data/maven/mqttgpio-min/target/mqttgpio-1.0-SNAPSHOT.jar
Yarn Resource Manager
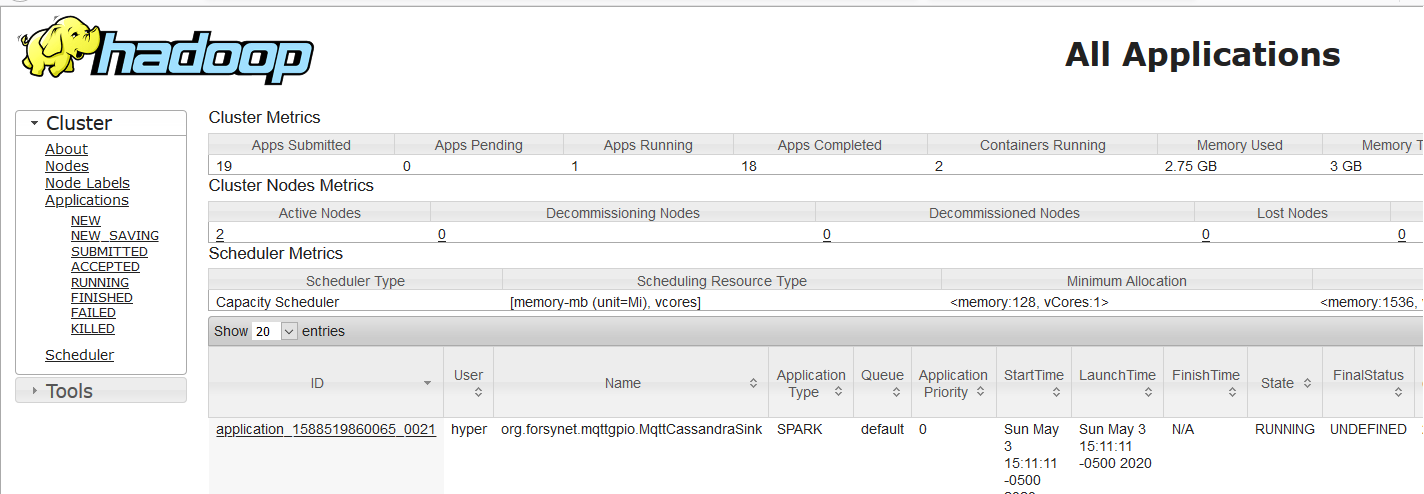
On the Resource Manager application row we can find the link for Spark Web UI for spark apps while they are running.
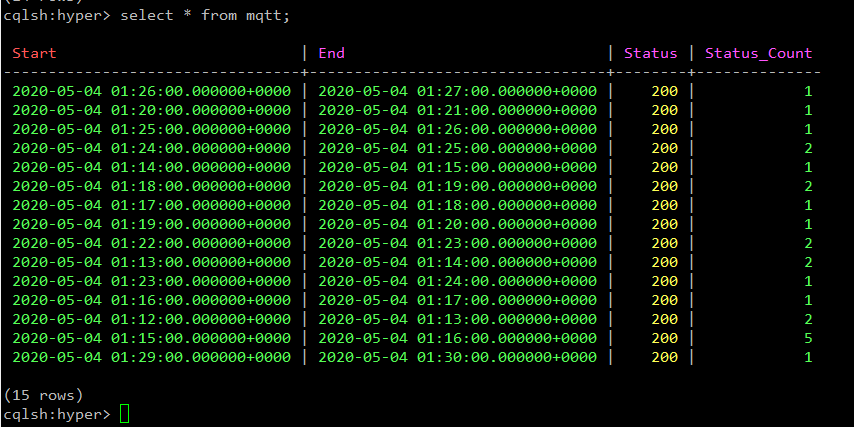
Finally Verify Cassandra DB for the data.
The code for this exercise can be found here