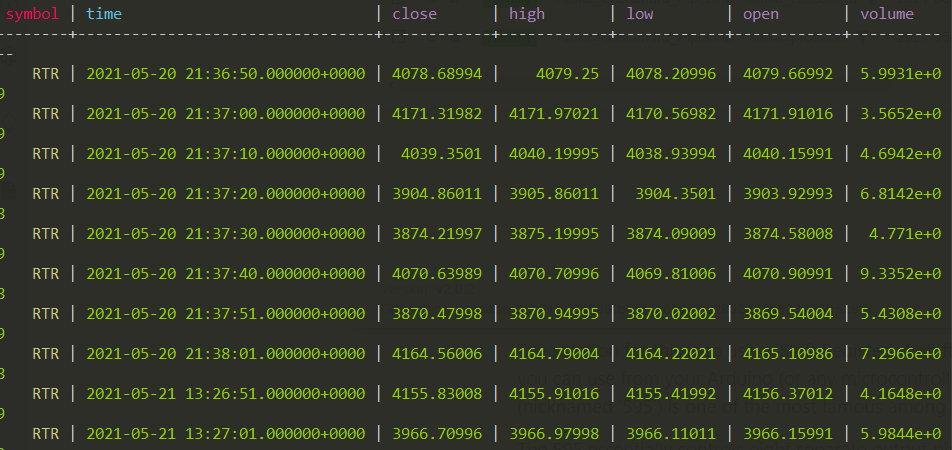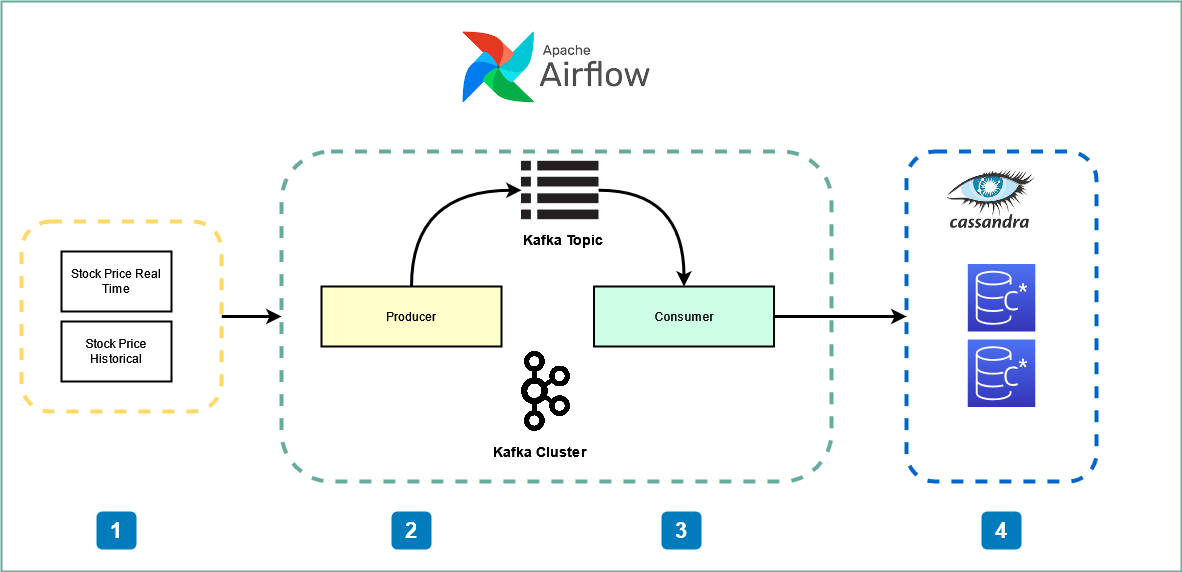
Business case : Create Airflow Pipeline using Kafka for Realtime stock price streaming, Cassandra for Realtime stock data warehousing
Real time stock price can be streamed from alphavantage.com(subscription required).I will be using fake stock data generator to simulate
In this exercise we will be using the following
- Kafka
- Airflow
- Cassandra
Refer git for further details
To run tasks parallelly in apache Airflow configure airflow with mysql so that it can run multiple threads.
# Make the below changes to airflow.cfg
sql_alchemy_conn = mysql://root:password@localhost/airflow_db
executor = LocalExecutor
# initialize the database
airflow db init
# start the web server, default port is 8080
airflow webserver -p 8090
# start the scheduler
airflow scheduler
#create airflow user
airflow users create -e rupesh@forsynet.com -f rupesh -l raghavan -p password -r Admin -u admin
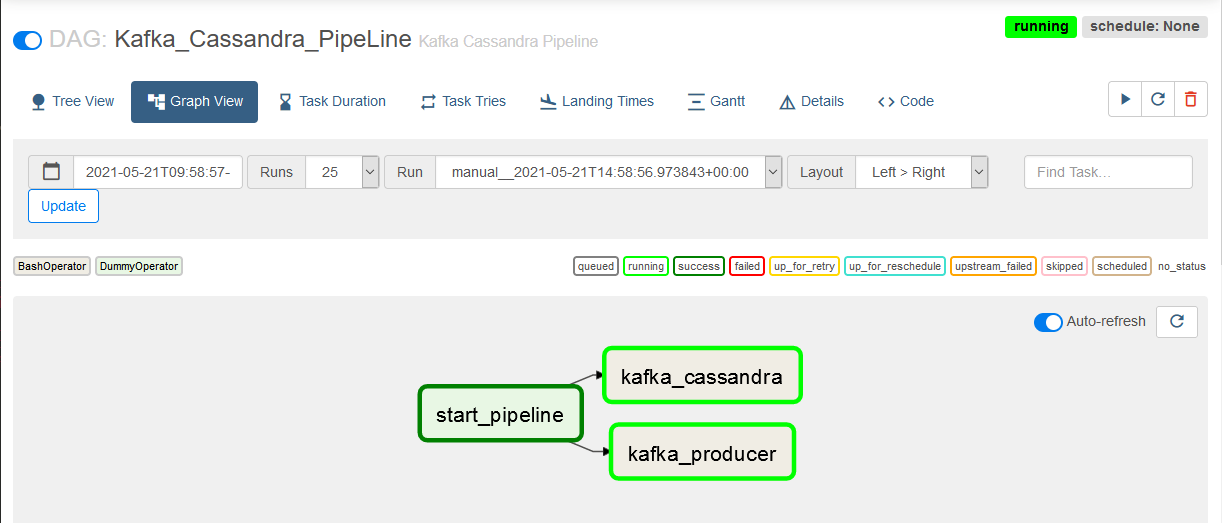
Airflow Tasks View
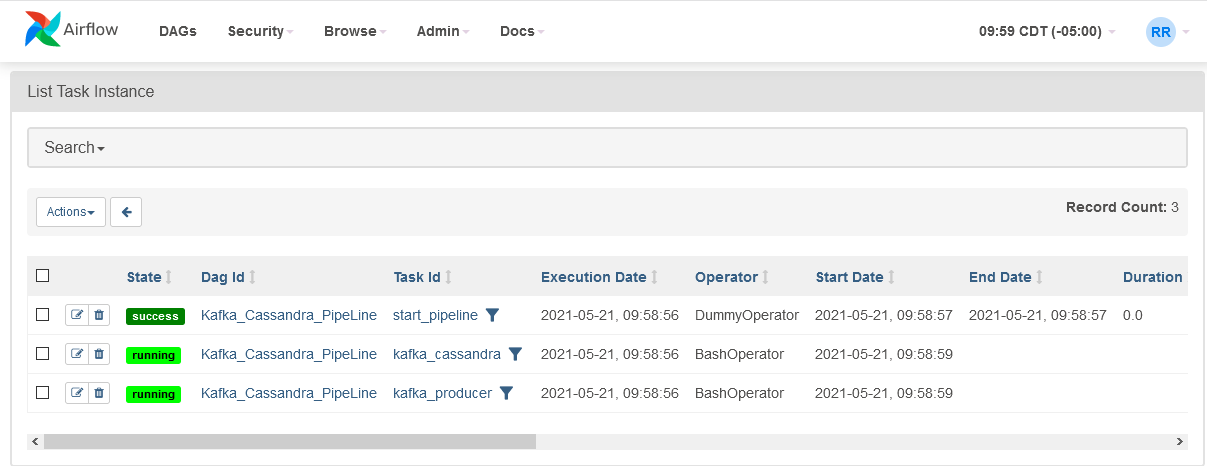
Airflow Dag
DAGs are a high-level outline that define the dependent and exclusive tasks that can be ordered and scheduled. To Create DAG create a Python file my_dag.py and save it inside the dags folder in airflow home
Airflow scheduler searches for python files in the dag directory and creates the dag**
from datetime import timedelta
from airflow import DAG
from airflow.operators.dummy import DummyOperator
from airflow.operators.bash import BashOperator
from airflow.utils.dates import days_ago
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'email': ['rupesh@forsynet.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=1),
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
# 'wait_for_downstream': False,
# 'dag': dag,
# 'sla': timedelta(hours=2),
# 'execution_timeout': timedelta(seconds=300),
# 'on_failure_callback': some_function,
# 'on_success_callback': some_other_function,
# 'on_retry_callback': another_function,
# 'sla_miss_callback': yet_another_function,
# 'trigger_rule': 'all_success'
}
# [END default_args]
# [START instantiate_dag]
with DAG(
'Kafka_Cassandra_PipeLine',
default_args=default_args,
description='Kafka Cassandra Pipeline',
schedule_interval=None,
start_date=days_ago(2),
tags=['kafka','cassandra'],
) as dag:
# [END instantiate_dag]
t0 = DummyOperator(
task_id='start_pipeline',
)
# t1, t2 are tasks created by instantiating bash operators
# [START kafka producer]
# space needed at the end of filepath.
t1 = BashOperator(
task_id='kafka_producer',
bash_command='/home/hyper/scripts/airflow_bash/run_producer.sh ',
)
t2 = BashOperator(
task_id='kafka_cassandra',
depends_on_past=False,
bash_command='/home/hyper/scripts/airflow_bash/run_cassandra.sh ',
)
# [END kafka consumer cassandra]
t0 >> [t1,t2]
# [END stocks pipeline]
Bash Command
#!/bin/bash
cd || exit
cd /home/hyper/scripts/stock_pipeline || exit
python -c 'from myKafkaProducer import run_producer; run_producer();'
Cassandra CQLSH