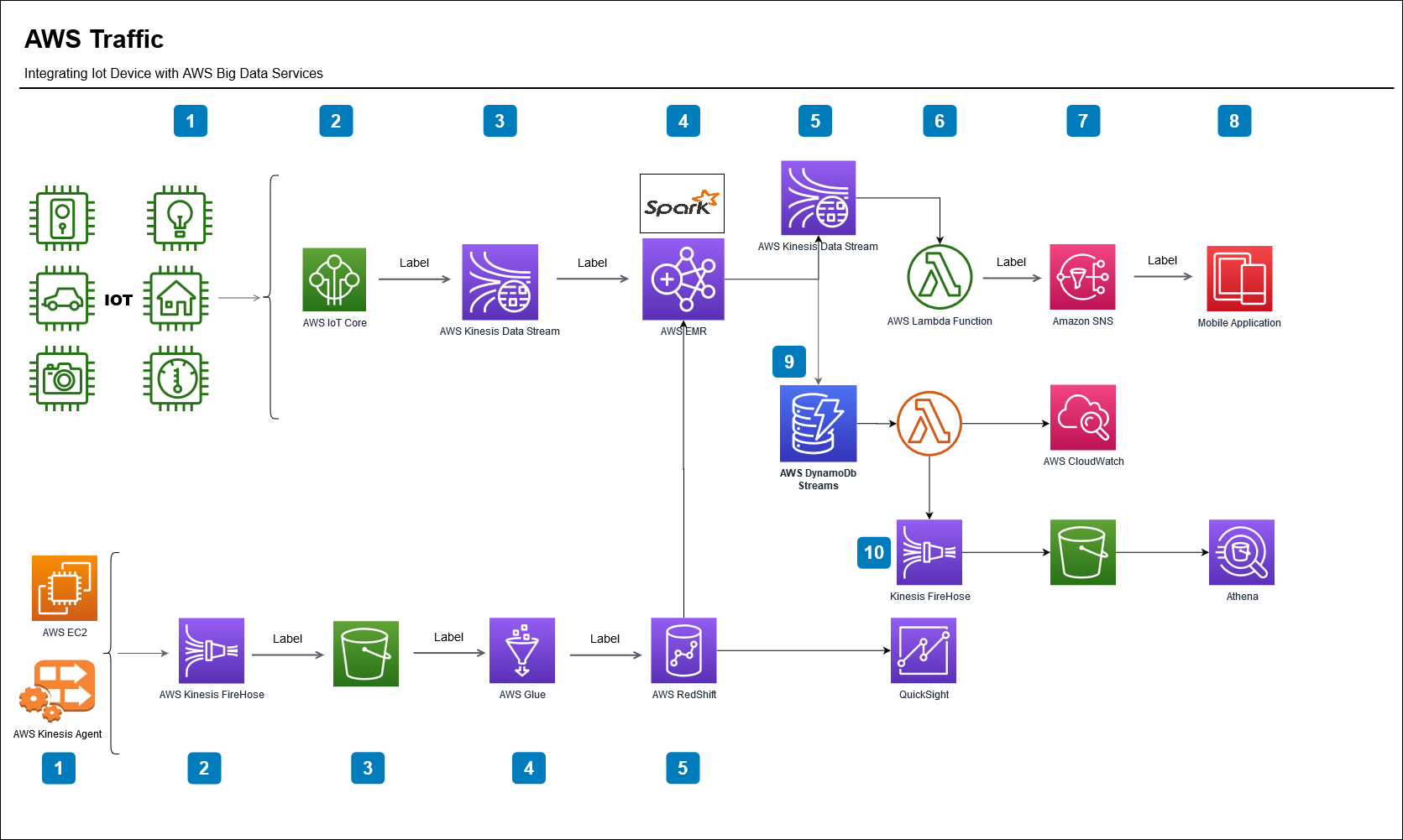
Business case :Use AWS Big data services to process streaming data from IOT device.
An Iot device will publish the license plate and clocked speed of vehicles as data streams into AWS and Spark Streaming for further processing.
AWS Spark job will filter the cars above speed limit ,Look up the vehicle owner information stored in Redshift data warehouse and eventually sends a SNS text message alert to the registered owner of the vehicle in real time.
AWS Services Used in this exercise.
- AWS IOT Core
- Kinesis Streams, Firehose, Analytics
- AWS RedShift
- AWS EMR
- AWS Lambda
- AWS SNS
- AWS Glue ETL , Crawler
- Spark Streaming
- DynamoDB , DynamoDB Streams
- EC2
IOT Data Flow
- Simulate the IOT device using a raspberry pi .Register the device with AWS IOT Core.
- On the IOT device when a button is pressed on breadboard will do a callback function to create a MQTT publish which sends the license plate and speed to AWS IOT Gateway.(NO image capturing mechanism publish script will read from a file and publish the data(licensePlate, longitude, latitude,city,state,speed).
- Define IOT Rules in AWS IOT core to send the data to Kinesis Stream
- AWS Emr Spark cluster will read the data from Kinesis Stream.
- Filter the speeding cars ,
- Lookup the driver information from Redshift based on license plate and
- Put records to outgoing kinesis stream with driver name and phone number information.
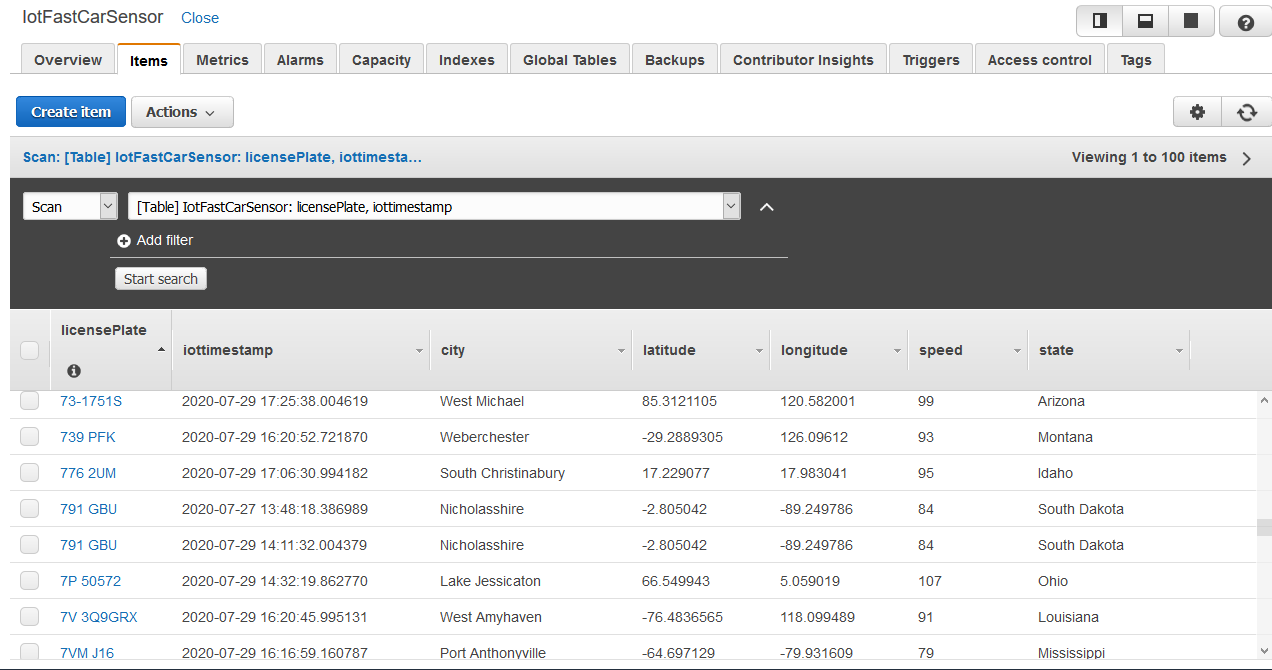
- Raw data will be written to a DynamoDB Table.
- AWS Lambda function will read this streaming data from Kinesis and publish to AWS SNS topic
- SNS will send the SMS message to the phone number of the owner registered with the license plate.
Redshift Data Flow
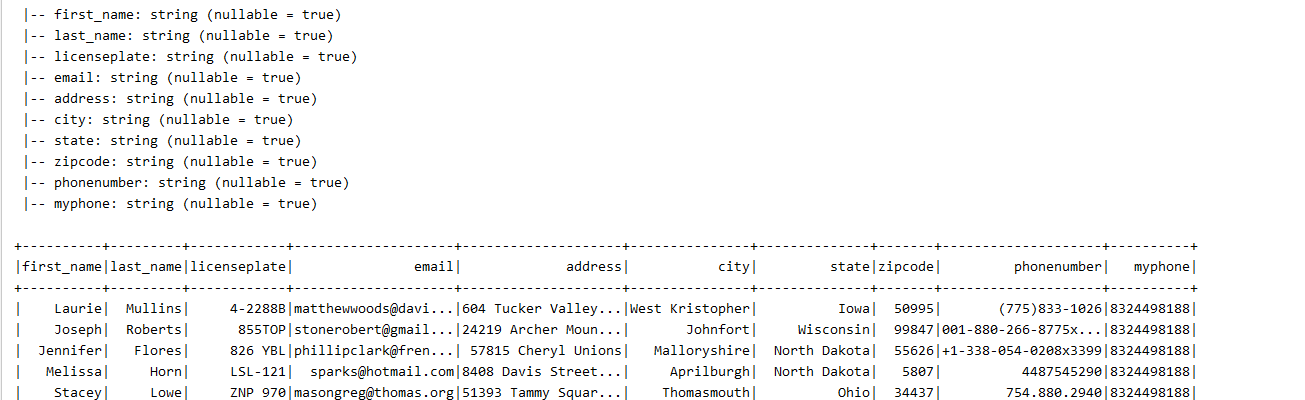
- We will use AWS Kinesis agent to read and the driver data from csv and put records to Kinesis Firehose. (first_name, last_name, licensePlate, email,address, city,state,zipcode,phoneNumber,myphone)
- Use Kinesis Firehose to load the data to S3 Bucket
- Use AWS Glue crawler , Glue ETL Job to load the data from S3 into Redshift Cluster using jdbc.
- The vehicle owner data in Redshift will be joined by the license plate from streaming data of speeding vehicles by AWS EMR Spark .
IOT Data Flow
Register IOT Thing in AWS IOT Core service
- Service AWS IOT Core -> Onboard
- Register a device in AWS IoT registry. IOT device needs a thing record in order to work with AWS IoT.
- Download a connection kit. Security credentials(.pem ,.key files), the SDK of your choice.(Python)
- Upload the connection kit zip file to device .
- Unzip connect_device_package.zip
- ./start.sh
- Subscribe the message topic under the test section in IOT core verify the communication with device. See the messages published under test section in IOT core.
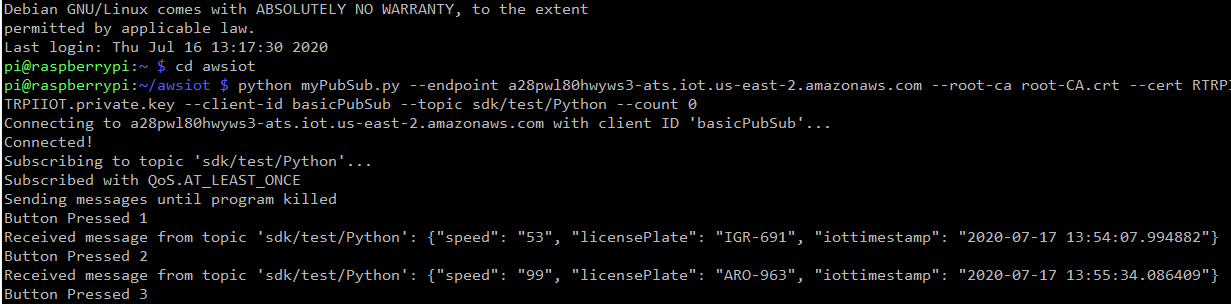
- Create your publish script and run the below command to run myPubSub.py which reads from a text file and send a json payload to the specified topic using MQTT publish subscribe protocol.
def mqttPublishLines(buttonPin):
publish_count = 1
filepath = "/home/pi/awsiot/mqtt/data/speeding_data.csv"
file = open(filepath, "r")
#line = file.readlines()
line = file.read().splitlines()
while (publish_count <= args.count) or (args.count == 0):
if GPIO.input(buttonPin)==GPIO.LOW:
payload = {"iottimestamp":str(datetime.utcnow()),
"licensePlate":line[publish_count].split(",")[0],
"longitude":line[publish_count].split(",")[1],
"latitude":line[publish_count].split(",")[2],
"city":line[publish_count].split(",")[3],
"state":line[publish_count].split(",")[4],
"speed":line[publish_count].split(",")[5] }
message = json.dumps(payload)
print("Button Pressed", publish_count)
GPIO.output(lightPin, True)
mqtt_connection.publish(
topic=args.topic,
payload=message,
qos=mqtt.QoS.AT_LEAST_ONCE)
time.sleep(1)
publish_count += 1
else:
GPIO.output(lightPin, False)
GPIO.add_event_detect(buttonPin,GPIO.BOTH,callback=mqttPublishLines,bouncetime=300)
Run Publish python script from IOT Device.
python iotPubSub.py --endpoint xxxxxxx.iot.us-east-2.amazonaws.com --root-ca root-CA.crt --cert RTRPIIOT.cert.pem --key RTRPIIOT.private.key --client-id basicPubSub --topic rtr/iot/trafficdata --count 0
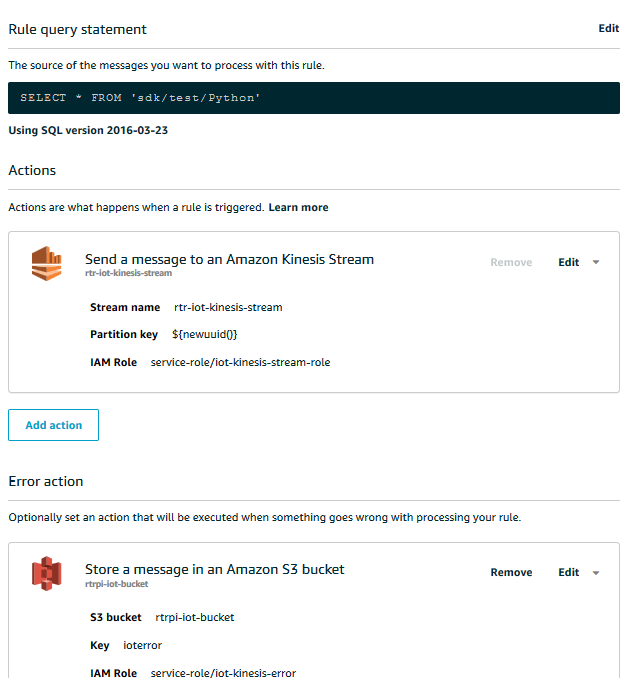
AWS IOT CORE
- Create AWS IOT Rule.
- Create Action and Select Send a message to an Amazon Kinesis Stream.
- Create AWS Kinesis Stream add stream to the action.
- Create Error Action for records in error.
- Enable the Rule.
Verify Data Getting Published to Kinesis Stream using Kinesis Analytics
AWS EMR
Spark job reads and processes the kinesis stream data as DStreams.
Provide DynamoDB table as checkpoint location in checkpointAppName parameter
// Kinesis DStreams create 1 Kinesis Receiver/input DStream for each shard
val kinesisStreams = (0 until numStreams).map { i =>
KinesisInputDStream.builder
.streamingContext(ssc)
.endpointUrl(endpointUrl)
.regionName(regionName)
.streamName(streamName)
.checkpointAppName(appName)
.initialPosition(new Latest())
.checkpointInterval(kinesisCheckpointInterval)
.storageLevel(StorageLevel.MEMORY_AND_DISK_2)
.build()
}
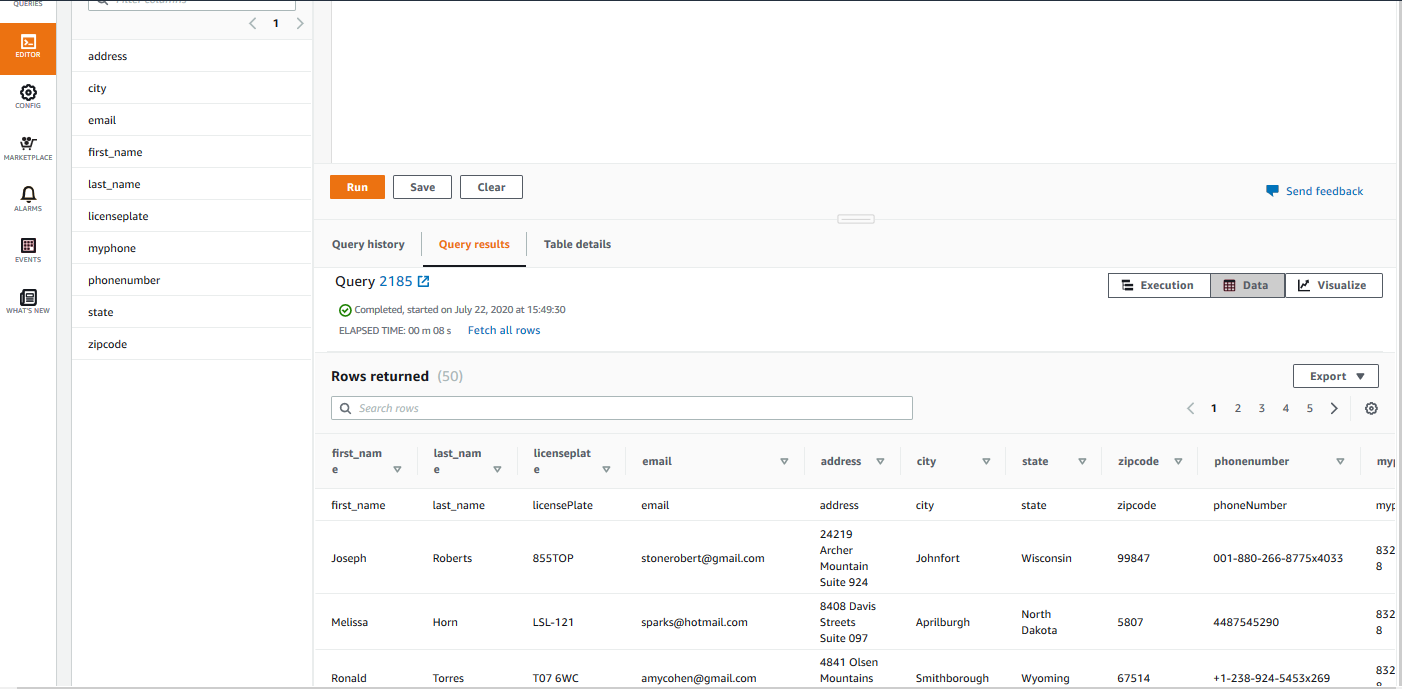
Method to Get Vehicle owner data from Redshift based on License Plate
def getDriverData(licenseplate:String) = {
val url = "jdb:url"
val user = "awsuser"
val redShifTable = "public.rtr_iot_driver_data"
// Get owner data from a Redshift table
val driverDf = spark.read
.format("jdbc")
.option("url",url)
.option("driver","com.amazon.redshift.jdbc42.Driver")
.option("user",user)
.option("password","We12come")
.option("dbtable",redShifTable )
.load()
.createOrReplaceTempView("driver_data")
spark.sql( s"select first_name,last_name,licenseplate,myphone from driver_data where licenseplate = '$licenseplate'")
}
Filter the Streaming DataSet for speeding vehicles above speed limit
val speedingVehicles = payLoadDs.filter(col("speed")>75)
- Join the streaming data frame with owner data from Redshift
- Publish Joined Data Frame to Kinesis Stream
- Put Record of the data in json format after joining with Driver Data and Speeding Dataframe into second Kinesis Stream
licensePlateDF.foreach(plate => {
println("Speeding plate",plate)
val driverData = getDriverData(plate)
// join condition between redshift df and streaming df
val joinCondition = speedingVehicles.col("licensePlate") === driverData.col("licenseplate")
// join the data frames using joinCondition
val speedingDriver = speedingVehicles.join(driverData, joinCondition, "inner").drop(driverData.col("licenseplate"))
println("Speeding driver details after df join")
speedingDriver.show()
val data = speedingDriver.toJSON.map(row => row.toString).collect()(0)
println("Speedign Drive Data toJson ",data)
val kinesisOutStream = "rtr-iot-kinesis-out-stream"
// Put the record onto the kinesis stream
val putRecordRequest = new PutRecordRequest()
putRecordRequest.setStreamName(kinesisOutStream)
putRecordRequest.setPartitionKey(String.valueOf(UUID.randomUUID()))
putRecordRequest.setData(ByteBuffer.wrap(data.getBytes()))
kinesisClient.putRecord(putRecordRequest)
})
Submit the Spark job from EMR Cluster
spark-submit iotkinesispark-assembly-0.1.jar IotKinesisCheckpoint rtr-iot-kinesis-stream IotFastCarSensor https://kinesis.us-east-2.amazonaws.com
EMR Logs
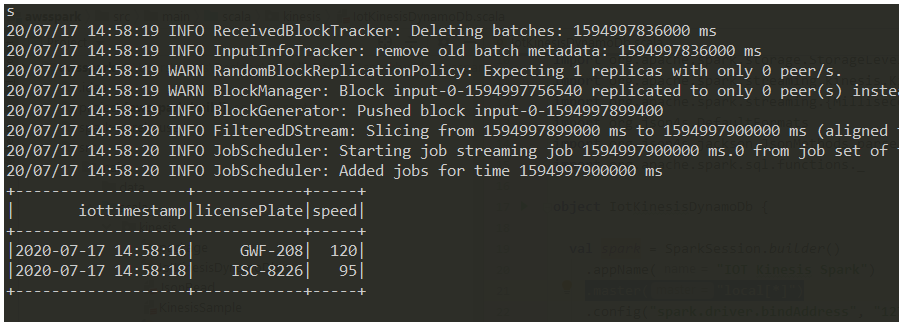
Verify Joined Data from Redshift and IOT Stream using Kinesis Analytics.
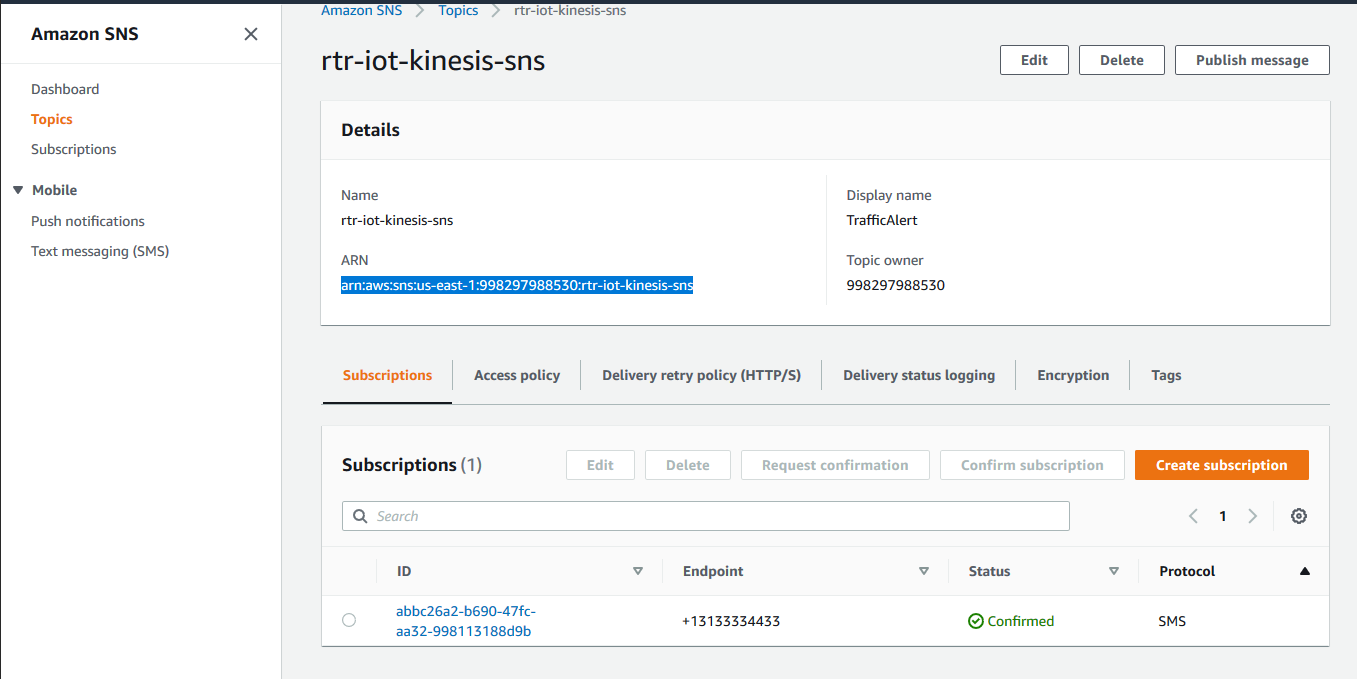
AWS SNS
Create Topic and Subscription in AWS SNS
AWS Lambda
Create AWS Lambda Function to Read from Kinesis Stream and Publish to SNS Topic.
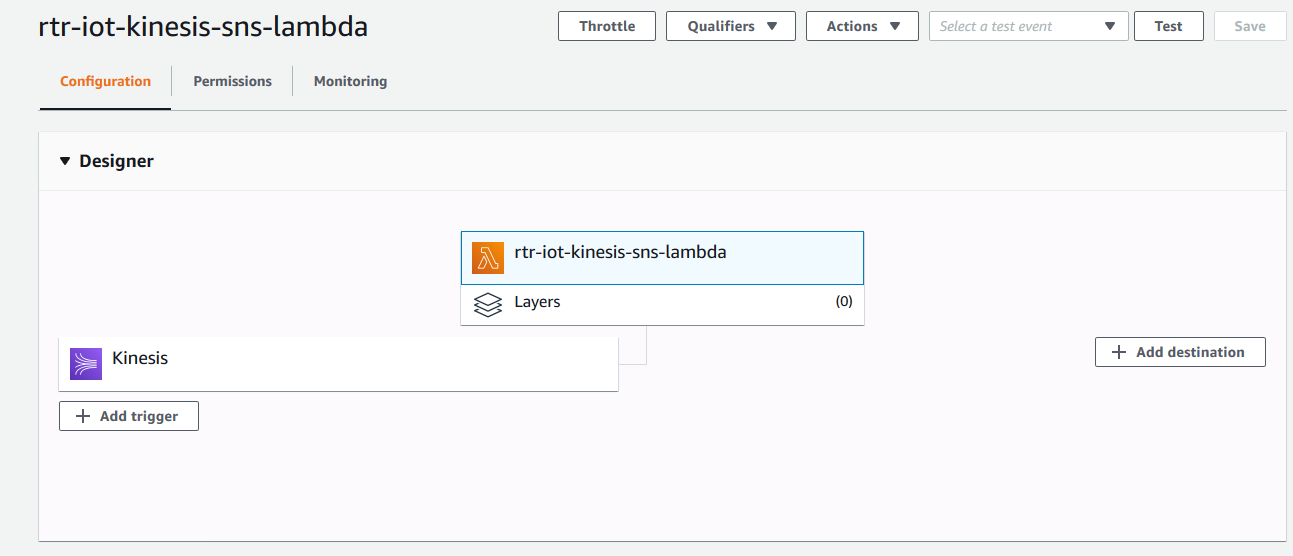
AWS Lambda Python Code Reads Stream Data and Publishes to SNS Topic,with Phone number from data stream passed as Endpoint argument.
phoneNumber = parsedPayload["myphone"]
e164phoneNumber = '+1'+phoneNumber
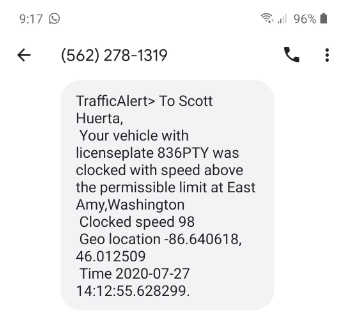
message_sns = "To {} {}, \n Your vehicle with licenseplate {} was clocked with speed above the permissible limit at {},{}\n Clocked speed {} \n Geo location {}, {} \n Time {}.".format(first_name,last_name,licensePlate,city,state,speed,longitude,latitude,iottimestamp)
logger.info(message_sns)
try:
client.subscribe(TopicArn=topic_arn,Protocol='sms', Endpoint=e164phoneNumber)
client.publish(TopicArn=topic_arn,Message=message_sns )
logger.info('Successfully delivered Speeding alarm message to {} '.format(phoneNumber))
except Exception:
logger.info('SNS Message Delivery failure')
End Result SMS Message Received from AWS SNS on the phone number of the owner of speeding vehicle.
DynamoDb Streams Data Flow
- The Speeding vehicle data will be also written to DynamoDb by AWS EMR Spark job.
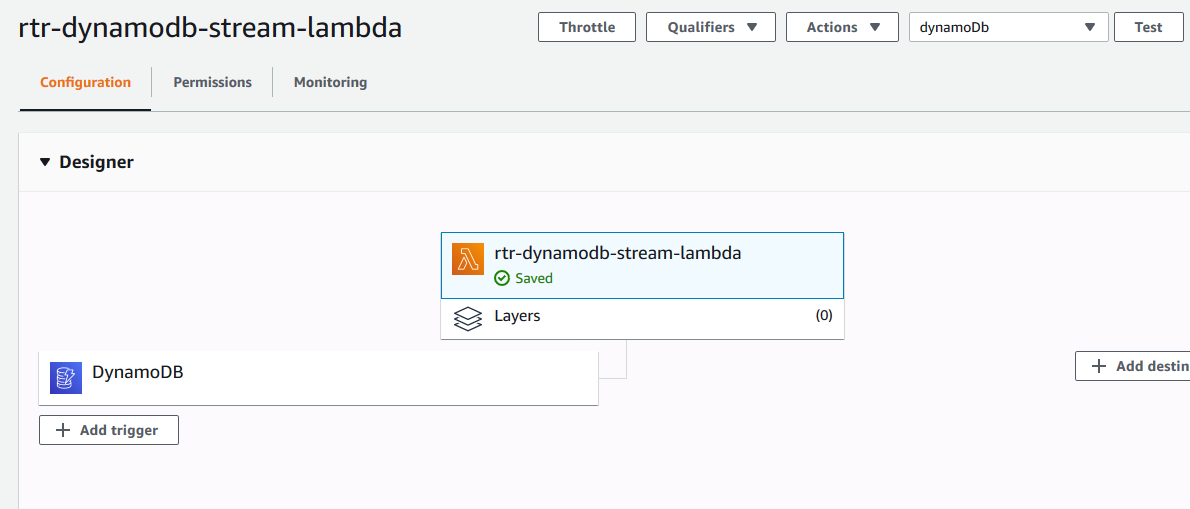
- Enable streaming on DynamoDB table and use lambda to read the data.
- AWS lambda will put the streaming records to a Kinesis FireHose Stream which will will save it to S3 destination.
Amazon EMR Spark script to write the Data to DynamoDb.
// write to dynamodb
speedingVehiclesDF.write
.format("com.audienceproject.spark.dynamodb.datasource")
.option("tableName", dynamoDbName)
.option("region",regionName)
.save()
- Enable Streams on the DynamoDb Table.
- Create Lambda Function which reads from the DynamoDb Stream and Publish to Kinesis Firehose.
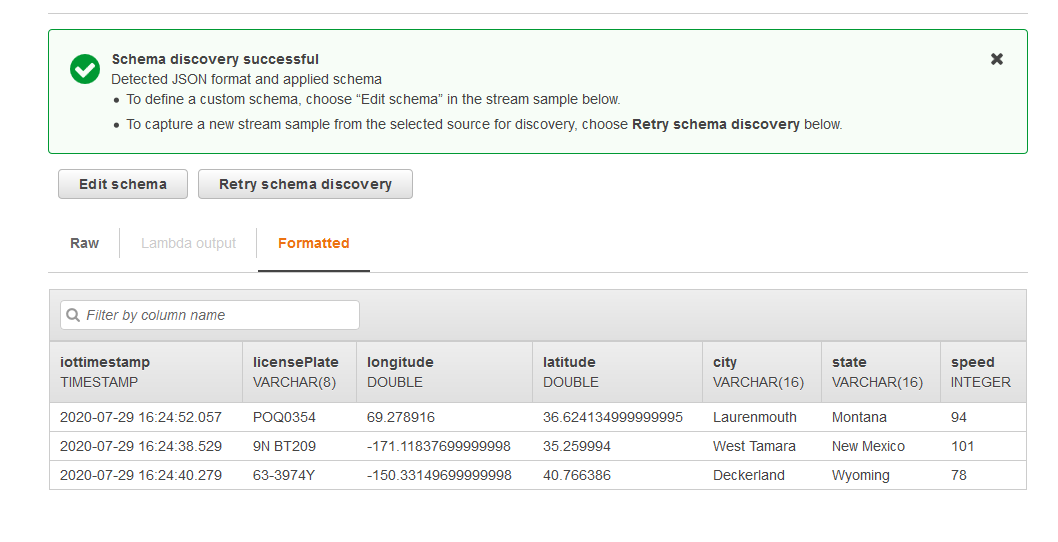
- Kinesis FireHose saves the data into S3 bucket in json.
record['dynamodb']
# logger.info('DDB Record: ' + json.dumps(ddbRecord))
parsedPayload = ddbRecord['NewImage']
logger.info('Firehose Record: ' + firehoseRecord)
firehose.put_record(DeliveryStreamName=deliveryStreamName, Record={ 'Data': firehoseRecord})
Verify the Kinesis Firehose Data Put records using Kinesis Analytics
References
-
Refer the git for data and code
- https://github.com/rupeshtr78/awsiot.git
- Data Generated Using Python Faker package.
- Recommended Courses
- Frank Kane
- Scala Spark
- https://rockthejvm.com